
Semantic journalism is a vision for the future of journalism. As the writer works on her article, her computer would gather data on the matter, from pictures to other articles to assessing global opinion trends. It would read through the Wikipedia pages of a given theme and summarize key concepts. A semantic algorithm would bring a selection of the most authoritative people on a subject.
The journalist is left with what she does best: checking and analyzing the data.
That means avoiding the pitfalls of redundant news content. That means escaping the trap of writing about topics without having a clue of what’s at stake. That means interviewing people who do things rather than those who talk about it.
This article is the first of a 4-part series. We’ll explore semantic hacks for newsgathering, writing and publishing in the coming weeks.
Part 1: Semantics today: What revolution?
Semantic journalism is closely related to the semantic web. The latter is a tidal wave redesigning the web since the early 2000’s, the motto of which is to make a webpage readable for machines. XML and RDF are the key words, Tim Berners-Lee the guru.
Now, having machines precisely understand the meaning of a story is another matter. Querying a database in natural language has been done since the 1970’s. Concretely, it means typing ‘What is the temperature in London?’ and seeing the machine display ‘20°C’.
But since the 1970’s, little has improved. Put simply, the computer reads the sentence, identifies a few words, their syntactical function and runs through a database to pick relevant information. Each word is given a meaning from the multiple senses it can carry.
In the example above, the computer can tell that ‘temperature’ is not referring to Sean Paul’s hit from the sentence’s structure. Then, it asks the database containing weather-related data for the current temperature in London.
Semantics rapid evolution has to do with Moore’s law and its army of escorting laws, all of which say that it’s getting cheaper to store and access data. Semantic applications can add more meanings to each word. Eventually, a semantic app will know that Temperature is also a 1937 movie. With a large enough database, it can store an almost infinite amount of temperature-related data.
However, when Sean Paul says that he ‘got the right temperature fi shelter you from the storm’, a computer will have a hard time understanding that there’s no actual shelter and no storm, no matter how many databases it commands. The key is to know that it’s a lush R&B song.
Some researchers argue that the traditional approach will not solve the semantic conundrum, no matter how much processing power is unleashed. Instead of a stratified method, where the program identifies the grammatical syntax, then the different possible meanings of each word, they favor a ‘what’s going on’ approach (they call it dynamic sense building, as opposed to compositional sense computing, in the words of semanticist Bernard Victorri).
In a paper, Daniel Kayser (full disclosure: that’s my dad) and Farid Nouioua explain that when a computer reads the sentence The truck in front of me braked suddenly, the key to extracting meaning isn’t in any of the words, but in knowing what is not said.
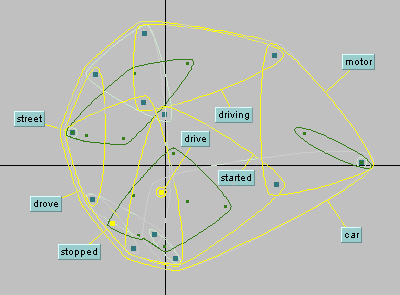
The semantic field for the word ‘car’, according to Sabine Ploux’s very cool semantic altlas
What the sentence actually means does not come by putting together the sense (as found in a dictionary) of each of its words. You need to know a lot about ordinary driving situations to grasp what any reader would find easily (e.g. the risk of accident was high). The knowledge required is not to be found in any dictionary or encyclopaedia, as thick as it might be. They argue that sense doesn’t come from what’s written, but from what’s assumed and left unwritten.
Semantics did not dramatically improve over the last decade. Automated summaries, for instance, a problem that has kept semanticists busy for the past 40 years, are still not expected for a distant future. Worse, it’s hard to see any technological lock that could, if broken, propel semantics into a higher gear.
In the coming weeks, the Online Journalism Blog team will test all kind of semantics apps that could help journalists. We’ll try to separate semantic snake-oil from genuinely innovative apps and discuss the value semantics can add. Stay tuned!

Pingback: links for 2008-06-25 | James Mitchell
Pingback: Journalism.co.uk Editors’ Blog » Blog Archive » links for 2008-06-26
Pingback: Jornalismo semântico : Ponto Media
Pingback: Web semântica: 3.0 ou apenas uma evolução? « SummerJOL 08
Pingback: Gimme your lunch money, kid « Content Ninja’s Weblog
Pingback: Primeiro Post, Objetivo e uma Definição « #jornalismosemântico