The latest “wife of” headline — ITV News’s report on the actor Lisa Faulkner revealing that she has undergone surgery after a cancer diagnosis — is an opportunity to get journalism students exploring how different forms of bias might shape news reporting — and not just the obvious ones.
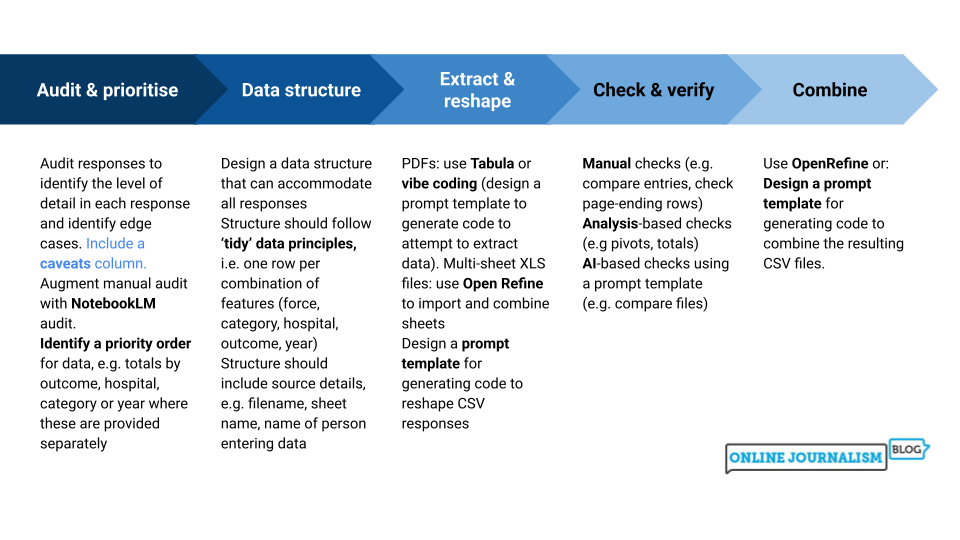
Sending FOIs to multiple bodies across the country to get the big picture on an issue sounds like a great idea — until the responses start to trickle in. Differences between responses often make mass FOI projects extremely time-consuming as you try to get everything into a format that allows you to ask journalistic questions and compare different authorities. Can AI help?
On one recent project I decided to put together a methodology that made the process less stressful, faster and more accurate. Here’s how it works.
Using visualisation on TV and video is very different to using charts and maps online. In video, the audience has very little time to absorb the information contained in the chart — so you need to get them to that information as quickly as possible.
Every bad example of charts in videos forgets this. And every good example uses two essential techniques: keeping things simple, and adding motion.
Some essential reading by Agnes Stenbom Swedling explores how news organisations integrate AI into their workflows and the idea of the “human in the loop“. Many newsrooms, she points out, “are not optimised for what humans do best”, and so far the introduction of AI hasn’t involved a critical consideration of whether we want to embed those features in new systems, or rethink them:
“What is being built – incrementally, often unintentionally – is a form of machine-centric hybridisation. Workflows are optimised for what machines do well: speed, scale, pattern recognition, cost efficiency. Humans are then positioned around those systems, adapting their tasks, roles, and decision-making to fit the logics of machines.
“The consequence is a subtle but significant inversion: rather than engaging in uniquely human activities, work is reorganised to fit machine-driven processes. And once that inversion is embedded at the infrastructural level, it becomes increasingly difficult to reverse.”
One of the most powerful ways to generate original journalism is to look at the systems behind stories — particularly the points where those systems fail.
For investigative work, those points are central. Surface-level scandals often stem from deeper systemic problems. So what tools do we have for recognising those patterns?
Donella Meadows’s classic book Thinking in Systems offers one: “system traps” — patterns that explain how systems get stuck, break down, or behave in ways nobody intends. They are “traps” because attempts to escape them often backfire.
In this post I’ll explain each trap, what it looks like in the wild, and how to use it as a lens for story ideas.
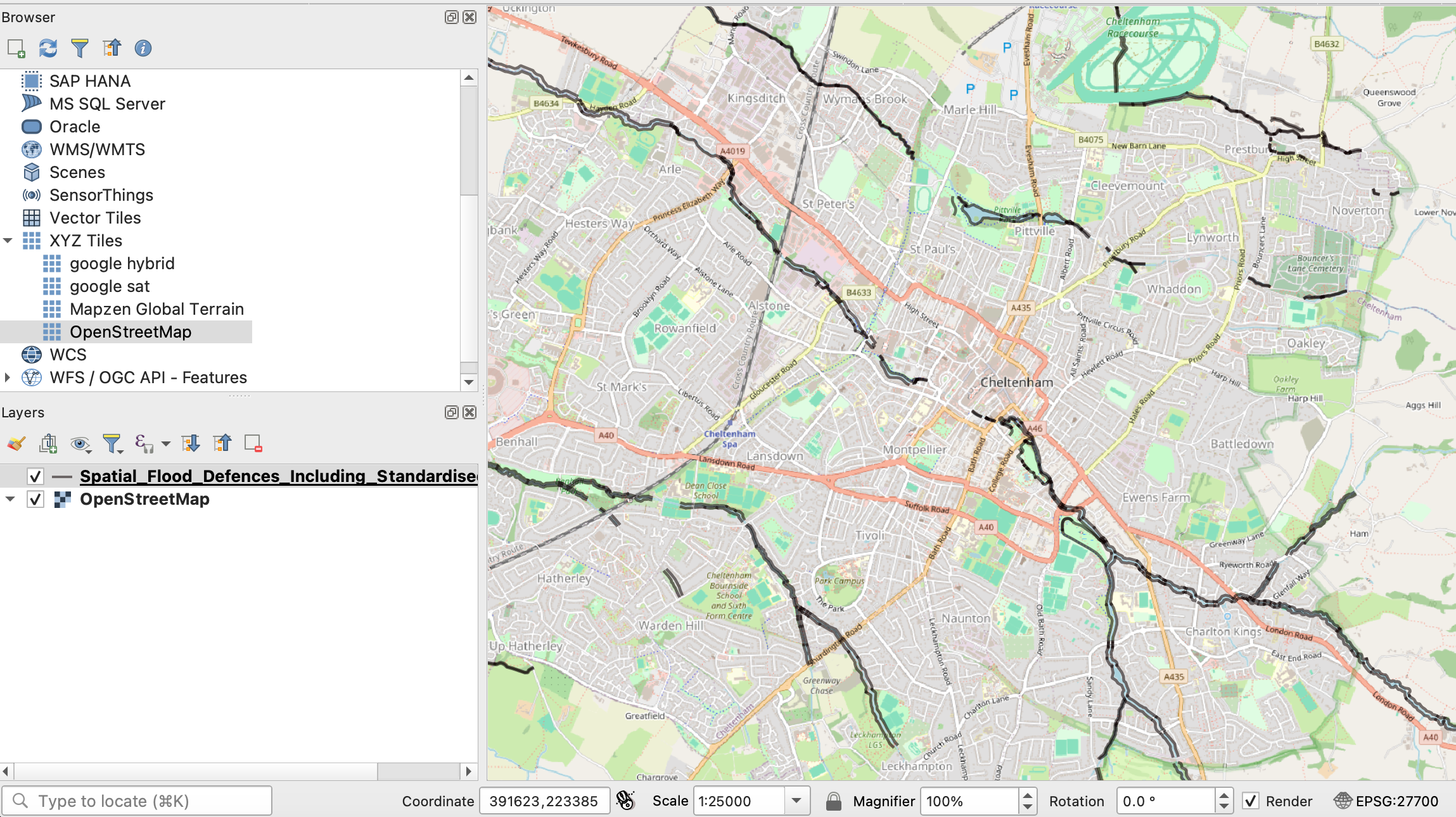
At this year’s Dataharvest I delivered a workshop on using Python in QGIS to automate the process of exporting maps for multiple locations. Here’s how to do it (you can find a GitHub repository with materials and links here).
Making a map for a story is cool — but what if you could make a map for every reader? Or if you’re working on a project involving teams in different regions or countries, what if you could give each one of those teams a map centred on their own patch?
Normally you would have to manually move the map to centre it on a key city, and then export an image. Then do it again and again and again for every area.
Luckily, QGIS has the ability to run code. And this is a great excuse to start using it.
By organising the layers on the left you can put shapes such as flood defences over a base OpenStreetMap layer. You can also change the scale in the box underneath the mapContinue reading →
In this latest post in the FAQ series, I am sharing some responses to a radio interview about AI’s impact on journalism.
Q: Is the continuous growth of AI-generated content online a danger for journalism?
It is certainly a problem yes, in three ways: it makes reporting harder, it makes it harder to support journalism financially, and it makes it harder for audiences to trust your reporting.
Documents and other collections of text can be goldmines for data journalism — if you know how to approach them as data. Here are some techniques and inspiration for your next data project.
Looking at those articles it’s clear that, once quantified, journalists tell the same stories about text as any other piece of data: using the seven most common angles.
But how those angles are used — and how often — is where it gets interesting…
One way to ensure you generate a wide range of potential sources for a story — or for potential story leads — is to use a checklist. The PEER framework is just that: four categories to help journalists generate more names on any given story — and think more creatively about whose voices might add something to that story.
PEER is a mnemonic (based on a previous post) for remembering the following four types of source:
💪 Power
🧠 Expertise
👁️🗨️ Experience
🗣️ Representative
Each type of source brings something different to the story: voices of power primarily (but not solely) answer questions about action: what was or is being done, what should or would be done about a particular issue. These are easily the most commonly quoted sources in news reporting.
People with expertise can answer the “why” and “how” questions — and are often more likely to speak to journalists — while those with experience can verify or validate (put a human face to) events. Representatives can speak to the wider impact or significance of an issue, or represent community sentiment about it.
Making each type of source explicit allows us to think about what those roles really mean — and identify less obvious ideas for sources with power, expertise, experience or representative qualities.
Freedom of Information (FOI) requests are not only one of the best ways to get original and exclusive stories that set your reporting apart — they’re also a good way to develop core journalism habits like curiosity, scepticism, and creativity. Here are some tips on how to get started with FOI while developing those qualities.
Being curious: how often is this happening? How much has it increased?
All these stories involve asking the question “how much” or “how many” about an issue or event
Curiosity is the first quality I identified in my series on the 7 habits of successful journalists — and FOI is a great way to hone that.
One good way to get started with FOI is to identify an event or problem that you’ve read about, and get curious about it: how many times is that event happening? How much is that problem costing? These are perfect questions for FOI.