In many countries public data is limited, and access to data is either restricted, or information provided by the authorities is not credible. So how do you obtain data for a story? Here are some techniques used by reporters around the world.
The most basic change to the Inverted Pyramid of Data Journalism is the recognition of a stage that precedes all others — idea generation — labelled ‘Conceive’ in the diagram above.
This is often a major stumbling block to people starting out with data journalism, and I’ve written a lot about it in recent years (see below for a full list).
The second major change is to make questioning more explicit as a process that (should) take place through all stages — not just in data analysis but in the way we question our sources, our ideas, and the reliability of the data itself.
A third change is to remove the ‘socialise‘ option from the communication pyramid: in conversation with Alexandra Stark I realised that this is covered sufficiently by the ‘utilise’ stage (i.e. making something useful socially).
Alongside the updated pyramid I’ve been using for the past few years I also wanted to round up links to a number of resources that relate to each stage. Here they are…
Python is an extremely powerful language for journalists who want to scrape information from online sources. This series of videos, made for students on the MA in Data Journalism at Birmingham City University, explains some core concepts to get started in Python, how to use Colab notebooks within Google Drive, and introduces some code to get started with scraping.
From January 23-25 I’ll be delivering a 3 day workshop on scraping in London at The Centre for Investigative Journalism. You don’t need any knowledge of scraping (automatically collecting information from multiple webpages or documents) or programming to take part.
By the end of the workshop you will be able to use scraping tools (without programming) and have the basis of the skills needed to write your own, more advanced and powerful, scrapers. You will also be able to communicate with programmers on relevant projects and think about editorial ideas for using scrapers.
A few weeks ago I announced that I was launching a new MA in Data Journalism, and promised that I would write more about the thinking behind it. Here, then, are some of the key ideas underpinning the new course — from coding and storytelling to security and relationships with industry — and how they have informed its development. Continue reading →
The best-known examples of data journalism tend to be based around text and visuals — but it’s harder to find data journalism in video and audio. Ahead of the launch of my new MA in Data Journalism I thought I would share my list of the examples of video data journalism that I use with students in exploring data storytelling across multiple platforms. If you have others, I’d love to hear about them.
FOI stories in broadcast journalism
Freedom of Information stories are one of the most common situations when broadcasters will have to deal with more in-depth data. These are often brought to life by through case studies and interviewing experts. Continue reading →
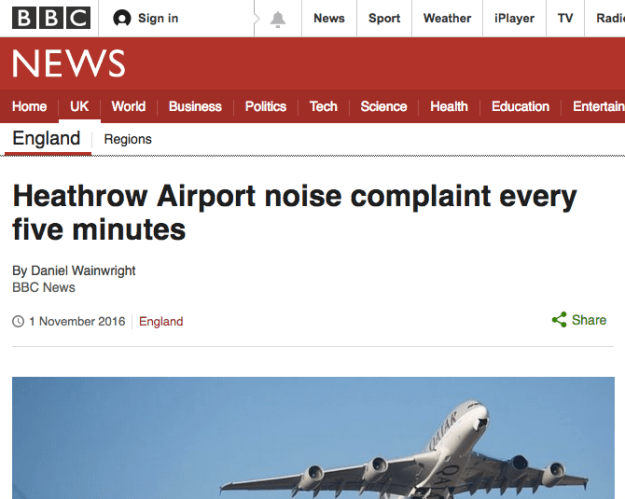
This news story used scraping to gather data on noise complaints
BBC England Data Unit’s Daniel Wainwright tried to explain basic web scraping at this year’s Data Journalism Conference but technical problems got in the way. This is what should have happened:
I’d wondered for a while why no-one who had talked about scraping at conferences had actually demonstrated the procedure. It seemed to me to be one of the most sought-after skills for any investigative journalist.
Then I tried to do so myself in an impromptu session at the first Data Journalism Conference in Birmingham (#DJUK16) and found out why: it’s not as easy as it’s supposed to look.
To anyone new to data journalism, a scraper is as close to magic as you get with a spreadsheet and no wand. Continue reading →
A screenshot from before the 2013 relaunch of Scraperwiki
7 years ago ScraperWiki launched with a plan to make scraping accessible to a wider public. It did this by creating an online space where people could easily write and run scrapers; and by making it possible to read and adapt scrapers written by other users (the ‘wiki’ part).
Mexican newspaper El Universal has put a face to the 4,534 women who have gone missing in Mexico City and the State of Mexico over the last decade:Ausencias Ignoradas (Ignored Absences) aims to put pressure on the government and eradicate this situation.
Daniela Guazo, from the data journalism team, explains how they gathered the data and presented the information not as numbers but as close people:Continue reading →
My Birmingham City University colleague Nick Moreton has a neat little hack for connecting a JavaScript app to social media accounts by combining the automation tool IFTTT, and Google Drive. As he explains:
“Most of the big web apps provide their API in JSON format (Facebook, Twitter, Instagram) however, as you may know if you’ve ever tried to use these, they often require an OAuth login in order to access the API.”