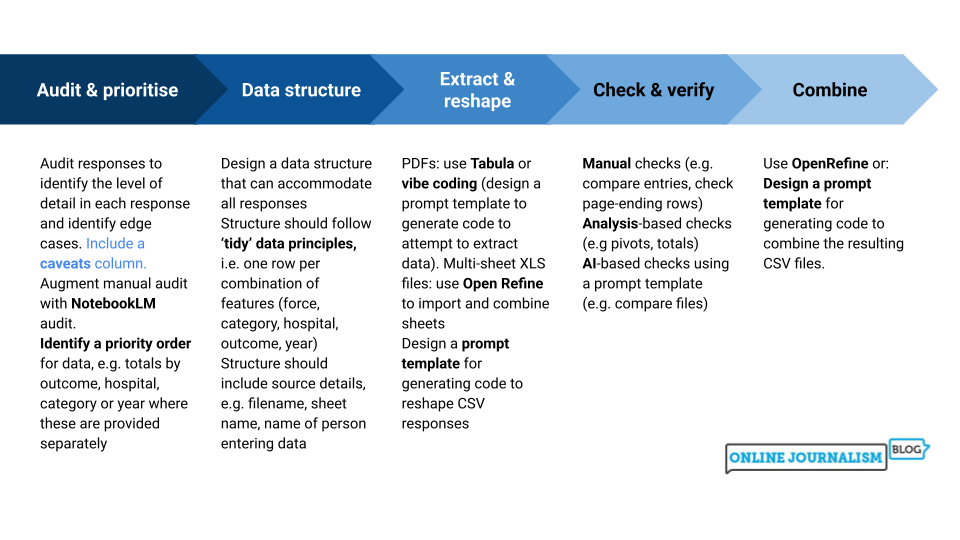
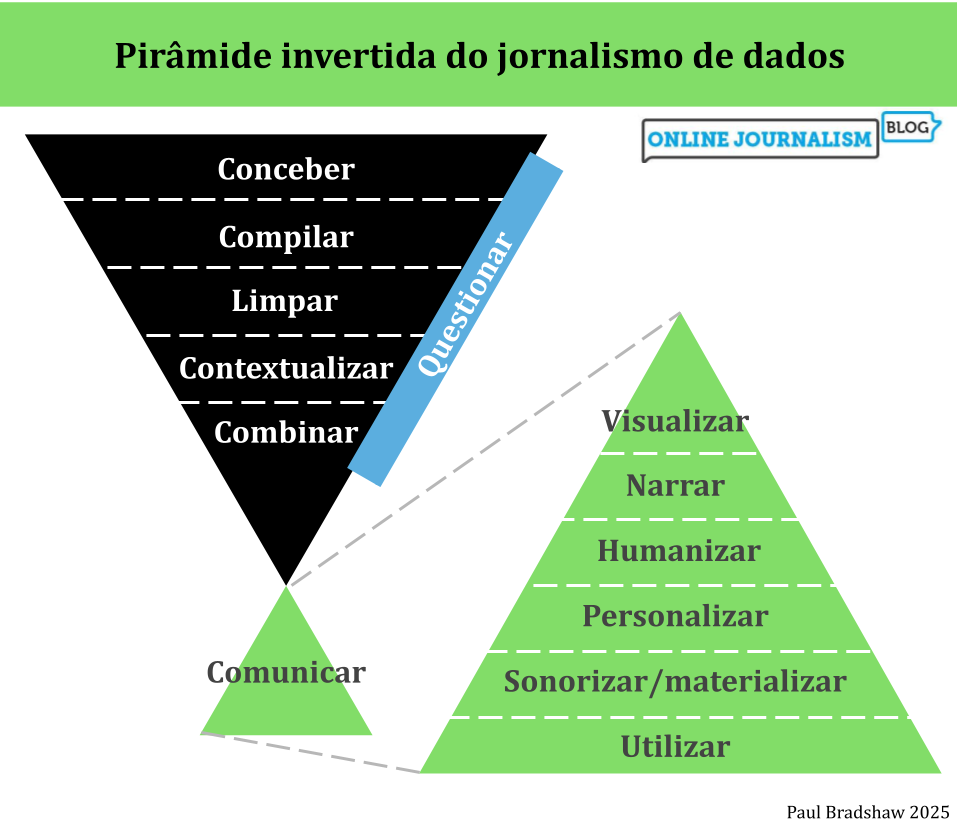
Sending FOIs to multiple bodies across the country to get the big picture on an issue sounds like a great idea — until the responses start to trickle in. Differences between responses often make mass FOI projects extremely time-consuming as you try to get everything into a format that allows you to ask journalistic questions and compare different authorities. Can AI help?
On one recent project I decided to put together a methodology that made the process less stressful, faster and more accurate. Here’s how it works.