
Cover design by Matt Buck/Drawnalism
My latest ebook – Finding Stories in Spreadsheets – is now live on Leanpub.
As with Scraping for Journalists, I’m publishing the book week-by-week so the book can be updated based on reader feedback, user suggestions and topical developments.
Each week you can download a new chapter covering a different technique for finding stories, from calculating proportions and changes, to combining data, cleaning it up, testing it, and extracting specific details.
There’s also a downloadable spreadsheet at the end of each chapter with a series of exercises to practise that chapter’s technique and find particular stories.
Along the way I tackle some other considerations in telling the story, such as context and background, and the importance of being specific in the language that you use.
If there’s anything you’d like covered in the book let me know. You can also buy the book in a ‘bundle’ with its sister title Data Journalism Heist, which covers quick-turnaround techniques for finding stories in spreadsheets using pivot tables and advanced filters.

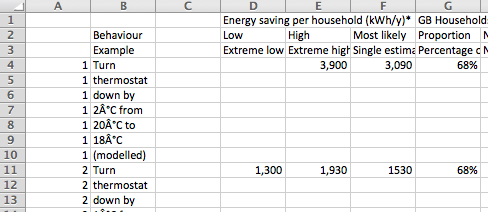 In this post I’ll explain how you can use Open Refine to quickly clean the data up so that the text is put back together and you have a single row for each entry. Continue reading
In this post I’ll explain how you can use Open Refine to quickly clean the data up so that the text is put back together and you have a single row for each entry. Continue reading 
 What is a reverse subscription model? Cedric Motte looks at what happens when you see digital as the heart of your distribution marketing and the paper as a commodity. This post was
What is a reverse subscription model? Cedric Motte looks at what happens when you see digital as the heart of your distribution marketing and the paper as a commodity. This post was 

