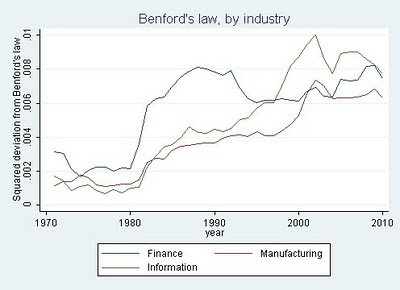
UPDATE [Feb 14 2012]: Full Fact picked up the challenge and dug into the data:
“The crucial difference is in methodology – while the TPA used individuals as its basis, the IFS used households as provided by the Government data.
“This led to substantially different conclusions. The IFS note that using household income as a measure demonstrates increased gains for households with two or more earners. As they state:
“”families with two taxpayers would gain more than families with one taxpayer, who tend to be worse off. Thus, overall, better-off families (although not the very richest) would tend to gain most in cash terms from this reform…””
—
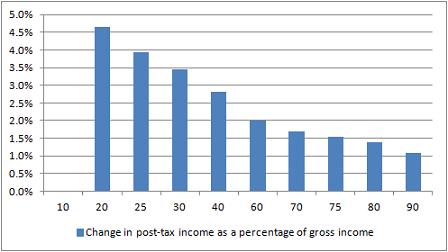
Here’s a great test for eagle-eyed journalists, tweeted by Guardian’s James Ball. It’s a tale of two charts that claim to show the impact of a change in the income tax threshold to £10,000. Here’s the first:
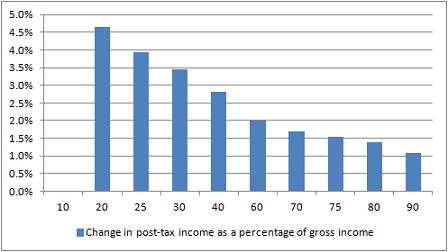
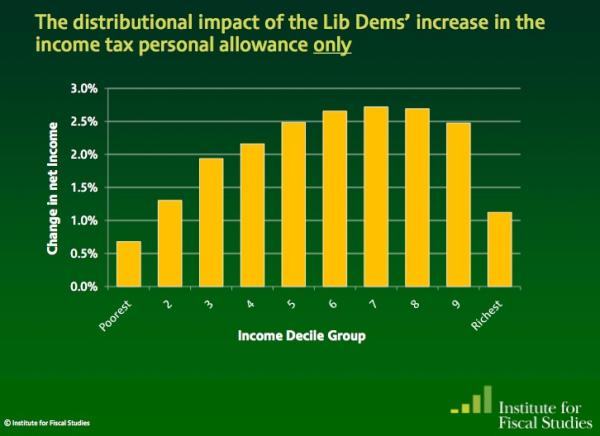
And here’s the second:
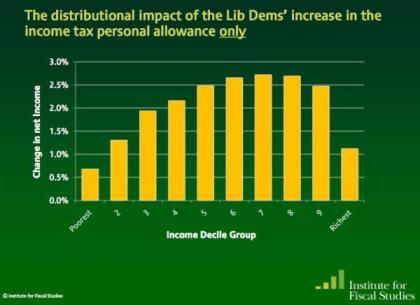
So: same change, very different stories. In one story (Institute for Fiscal Studies) it is the the wealthiest that appear to benefit the most; but in the other (Taxpayers’ Alliance via Guido Fawkes) it’s the poorest who are benefiting.
Did you spot the difference? The different y axis is a slight clue – the first chart covers a wider range of change – but it’s the legend that gives the biggest hint: one is measuring change as a percentage of gross income (before, well, taxes); the other as a change in net income (after tax).
James’s colleague Mary Hamilton put it like this: “4.5% of very little is of course much less than 1% of loads.” Or, more specifically: 4.6% of £10,853 (the second decile mentioned in Fawkes’ post) is £499.24; 1.1% of £47,000 (the 9th decile according to the same ONS figures) is £517. (Without raw data, it’s hard to judge what figures are being used – if you include earnings over that £47k marker then it changes things, for example, and there’s no link to the net earnings).
In a nutshell, like James, I’m not entirely sure why they differ so strikingly. So, further statistical analysis welcome.
UPDATE: Seems a bit of a Twitter fight erupted between Guido Fawkes and James Ball over the source of the IFS data. James links to this pre-election document containing the chart and this one on ‘Budget 2011’. Guido says the chart’s “projections were based on policy forecasts that didn’t pan out”. I’ve not had the chance to properly scrutinise the claims of either James or Guido. I’ve also yet to see a direct link to the Taxpayers’ Alliance data, so that is equally in need of unpicking.
In this post, however, my point isn’t to do with the specific issue (or who is ‘right’) but rather how it can be presented in different ways, and the importance of having access to the raw data to ‘unspin’ it.