Too often discussion around using AI is “either/or” — an assumption that you either use AI for a task, or do it yourself. But there’s another option: do both.
“Parallel prompting“* is the term I use for this: while you perform a task manually, you also get the AI to perform the same task algorithmically.
For example, you might brainstorm ideas for a story while asking ChatGPT to do the same. Or you might look for potential leads in a company report — and upload it to NotebookLM to perform the same task. You might draft an FOI request but get Claude to draft one too, or get Copilot to rewrite the intro to a story while you attempt the same thing.
Q: What skills do you think a journalist must absolutely have when working with data?
There are three core skills I always begin with: sorting, filtering, and calculating percentages (proportion and change). You can do most data journalism stories with those alone.
Alongside those basic technical skills it’s important to have the basic editorial skills of checking a source against other sources (following up your data by getting quotes or interviews), and being able to communicate what you’ve found clearly for a particular audience.
In the latest FAQ, I’m publishing here answers to some questions from a Turkish PR company (published on LinkedIn here)…
Q: In your view, what has been the most significant transformation in digital journalism in recent years?
There have been so many major transformations in the last 15 years. Mobile phones in particular have radically transformed both production and consumption — but having been through all those changes, AI feels like a biggest transformation than all the changes that we’ve already been through.
It’s not just playing a role in transforming the way we produce stories, it’s also involved in major changes around what happens with those stories in terms of how they are distributed, consumed, and even how they are perceived: the rise of AI slop and AI-facilitated misinformation is going to radically accelerate the lack of trust in information (not just the media specifically). I’m being careful to say ‘playing a role’ because of course the technology itself doesn’t do anything: it’s how that technology is designed by people and used by people.
Double counting — counting something more than once in data — can present particular risks for journalists, leading to an incorrect total or proportion. Here’s how to spot it — and what to do about it.
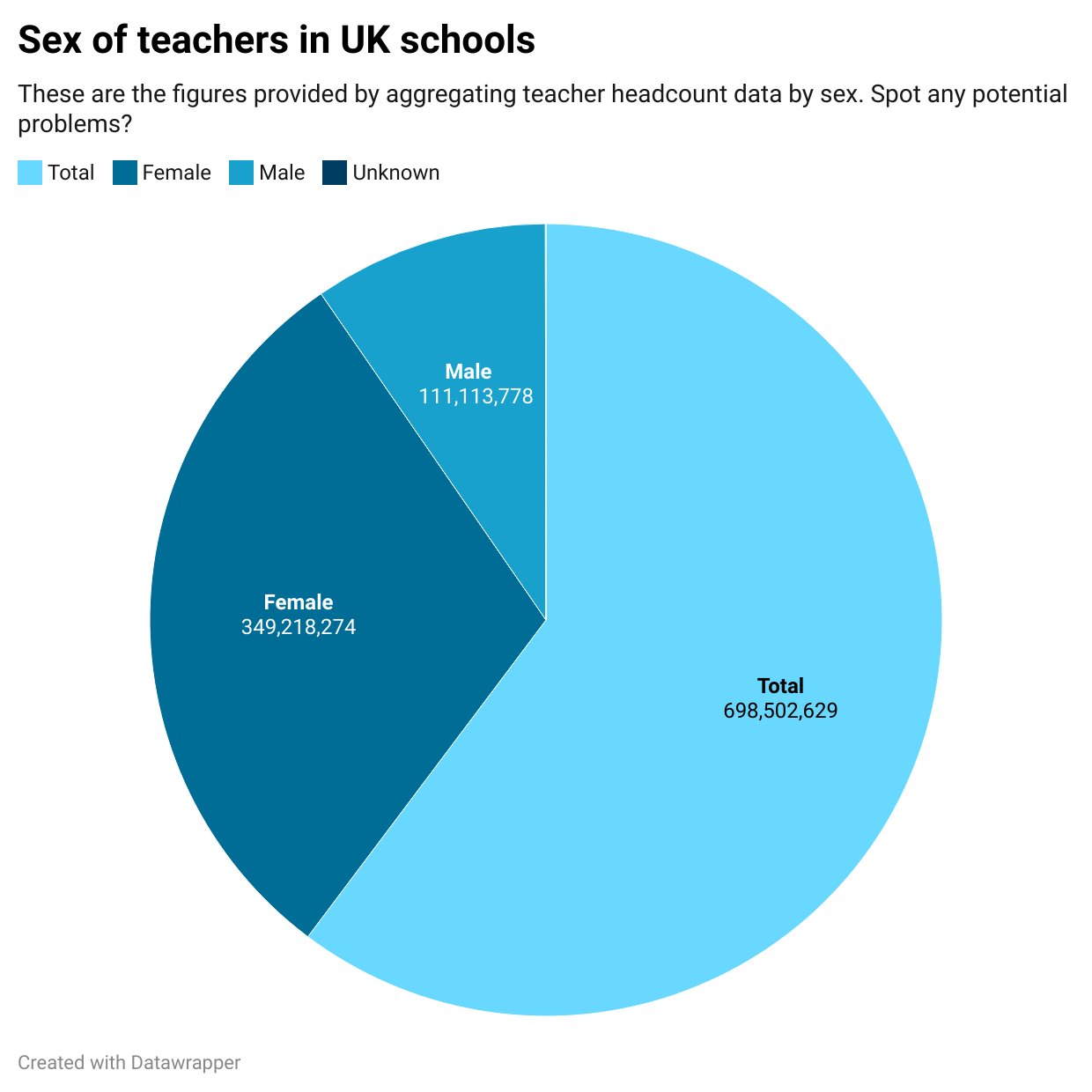
Look at the following chart showing the gender of teachers in UK schools, based on data on teacher headcounts. Notice anything wrong? (There are at least two problems)
The most obvious problem is that the chart appears to be ‘comparing apples with oranges’ (things that aren’t comparable). Specifically: “male”, “female”, and “unknown” are similar categories which can fairly be compared with each other, but “total” is a wider category that contains the other three.
I’ve used a pie chart here to make it easier to spot: we expect a pie chart to show parts of a whole, not the whole as well as its parts.
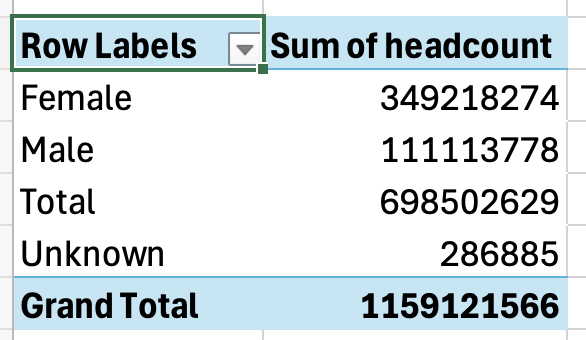
But the same problem should be obvious from the same data in a table before visualising it:
The table shows us that we have both a “Total” and a “Grand Total”. This is a red flag. There can only be one total, so if there’s more than one that’s a strong sign of double counting.
Why is this happening? We need to take a look at the data.
Are journalists only ever born with a passion for their craft — or is it something that can be taught?
Of all the seven habits that have been explored in this series, passion is perhaps the one that seems most innate — a quality that you “either have or don’t have”.
Can we teach passion? Well, we can provide the reasons why someone might be passionate about their craft — we can inspire passion and we can create opportunities to experience the things that have stimulated passion in others. Continue reading →
While many are attracted to journalism because of its opportunities for creative expression, few are attracted by its various constraints. But it is those particular contraints which make journalism distinctive, and separate from other creative work such as art or fiction.
In fact you might argue that it is constraints that make journalism more similar to creative fields such as design, where the functionality and user of the work must be considered, leading to increasing cross-pollenation between them (e.g. the rise of design thinking in journalism).
These constraints can be broadly classed as aspects of the work that require self-control, or discipline. For example:
We must consider the audience in the selection and treatment of stories
We must hit regular deadlines
We must write within a particular word count or to particular timings
We must remain impartial and objective in our reporting (in most genres)
These aspects of discipline are reflected in some of the most common feedback given to trainee journalists: Continue reading →
Describing journalism as a creative profession can cause discomfort for some reporters: we portray journalism as a neutral activity — “Just the facts” — different to fiction or arts that appear to ‘create something from nothing’.
But journalism is absolutely a creative endeavour: we must choose how to tell our stories: where to point the camera (literally or metaphorically), how to frame the shot, where to cut and what to retain and discard, and how to combine the results to tell a story succinctly, accurately and fairly (not always the story we set out to tell).
We must use creativity to solveproblems that might prevent us getting the ‘camera’ in that position in the first place, to find the people with newsworthy stories to tell, to adapt when we can’t find the information we want, or it doesn’t say what we expected (in fact, factual storytelling requires an extra level of creativity given that we can only work with the truth).
All of those are creative decisions.
And before all of that, we must come up with ideas for stories too. The journalist who relies entirely on press releases is rightly sneered at: it is a sign of a lack of imagination when a reporter cannot generate their own ideas about where to look for news leads, or how to pursue those. Continue reading →
Empathy is the first stage of design thinking. Image: Mike Boyson
In the fourth of a series of post on seven habits often associated with good journalism I look at a quality which is much less talked about, and often misunderstood — and why I believe it should be just as central as qualities such as persistence or curiosity.
Empathy — specifically cognitive empathy — is the ability to imagine what it is like to be in someone else’s shoes.
It is one of the more underrated qualities of good journalists, perhaps because people often confuse it with sympathy, or with emotional empathy.
The difference is important: it is possible to imagine what it is like to be a particular person (cognitive empathy), including criminals and corrupt officials, without feeling sorry for them (sympathy) or feeling the same way (emotional empathy). Continue reading →
One of the earliest skills that broadcast journalists learn is how to conduct a vox pop. The vox pop is an attempt to ‘take the pulse’ of the public on a topical issue: the journalist will stand in a busy public place and ask passers-by to share their thoughts on the issue of the day.
The results will typically be used as part of a news package (not, it should be pointed out, as a standalone story), particularly when the news story in question doesn’t have many other interviews or visuals to draw on. Most are quickly forgotten. Continue reading →