

Previously I wrote about four of the 7 angles that are used to tell stories about data. In this second part I look at the three further angles: those stories focusing on relationships; ‘meta data’ angles that focus on data’s absence, poor quality, or collection — and exploratory features that mix multiple angles or provide an opportunity to get to the grips with the data itself.
Data angle 5. ‘Explore’: tools, interactivity — and art
There are two broad categories of exploratory story:
- Interactive stories characterised by an explicit ‘call to action’ like “explore”, “play” or “Take the quiz” — or a more implicit invitation to users to explore what has been “Mapped” or “Every X that ever happened”; and
- Exploratory features that raise (and then answer) a question. These features often combine more than one of the first three angles (scale, change, ranking) or apply the angle to more than one measure or category. The key quality is that the core angle of the feature is ‘we explore’ multiple aspects rather than ‘we reveal the scale/rank/change’ of one main thing.
An interactive explanatory story often invites readers to explore data in order to generate a personal version of it. The data could be presented in quizzes (such as the BBC’s ‘7 billion people and you: What’s your number?‘ and the New York Times’s ‘Take the Quiz: Could You Manage as a Poor American?‘) or maps like the LA Times’ ‘Every shot Kobe Bryant ever took. All 30,699 of them‘.
This category also takes in simulators like the Washington Post’s record-breaking ‘Why outbreaks like coronavirus spread exponentially, and how to “flatten the curve”‘ and Matt Korostoff’s ‘Wealth shown to scale‘, as well as games, calculators, and chatbots, among other formats.
Exploratory features might look at “why”, “how”, or “where” something happened or is happening, “who” is involved or affected, or “what” you need to know.
The Guardian’s ‘Who is dying from coronavirus and in which NHS trusts?‘ is exploratory in offering broad insights and a static map, for example, and Bloomberg’s excellent narrated visualisations such as How Americans Die allow some interaction with the charts but are strongly author-driven.
They can also be quite quirky — even a form of art. ‘Sweet Love: Popular Wedding Songs Reimagined As Cupcakes‘, for example, is simply an exploration of what happens when playlists are treated as data and that data is visualised in a particular way.
Data angle 6. Relationships and debunking: when things are connected — or not
Journalists often seek to establish relationships by looking at data, but this can be problematic: correlation is, of course, not the same as causation, so even though two things may be going up or down at the same time it does not mean that the two are related — as The Guardian’s ‘Is rise in violent crime due to cuts to neighbourhood policing?‘ explores.
For that reason it is perhaps just as often that you will see a story debunking a relationship between two data points as you will see one trying to establish that X is causing Y.
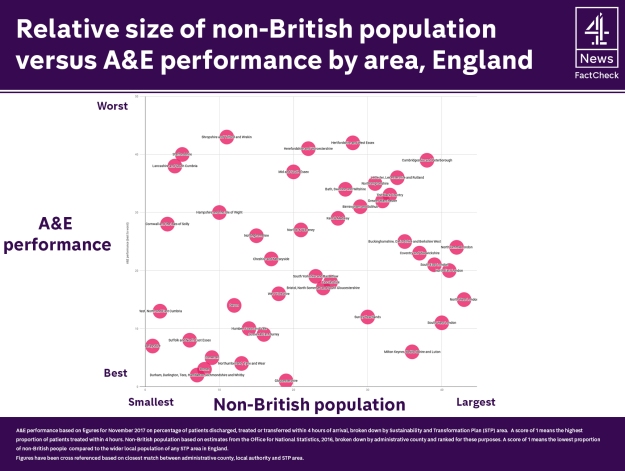
Channel 4 News’s FactCheck, for example, looked at data to answer the question ‘Are migrants causing the A&E crisis?‘ and found no relationship between the size of non-British population in an area and A&E performance.
Equally, you may find that it is better to switch from an angle focusing primarily on revealing a relationship, to instead lead on an explanatory angle that allows you to dig into the complexities of multiple variables involved alongside expert comment on the extent to which those relationships might be causal or not.
The Economist’s ‘How an obsession with home ownership can ruin the economy‘, for example, is an explanatory story rather than a relationship story: it spends over 12 minutes exploring the relationship between those two variables rather than pitching the story as a ‘revealing’ that home ownership is ruining the economy.
Relationship stories don’t have to be about correlation: network analysis offers another way of telling stories which are grounded in factually established relationships such as donations, directorships, family connections, social media follows or other interactions.
The project ‘Investigating Google’s revolving door‘, for example, uses data to expose the number of people moving between the tech giant and government bodies, while The Seattle Times’s ‘In Seattle art world, women run the show‘ uses a network diagram visualisation to tell the story of connections within the local art scene (built by asking women “in the Seattle-area art community to name mentors, collaborators and peers who have influenced their careers.”)

But even network analysis can lack concreteness: a connection between two people or a movement between organisations is rarely proof alone of corruption or ‘causation’ of suspect-looking decisions.
For that reason network analysis is also often presented as an exploratory story (‘Australian political donations 2016-17: who gave what to which parties‘), as part of an explanatory feature (‘Radiohead’s corporate empire: inside the band’s dollars and cents‘), or the process is used to identify a single data point based on its relationships, which then informs further reporting (‘Top Tory has family link with offshore banker who gave party £800,000‘).
Many of the stories to come out of the Panama Papers, for example, come under this latter category, and the ICIJ’s The Power Players is an exploratory angle on the various stories that the documents helped uncover.
Reuters’s Connected China is one of the best examples of navigating the challenges of network-based storytelling, leading you carefully through the structures of power it has mapped out and allowing you to explore along the way.
Data angle 7: Problems and solutions: bad data, ‘no data’, and ‘get the data’ stories
The final category of story may feel a little bit ‘meta’ — stories about data itself: the lack of it, the problems with it, or simply its availability — but that doesn’t mean it might not be a good story.
‘Bad data’ stories can be incredibly important: power is exercised, money spent, and lives affected on the basis of data so if the data is flawed then the exercise of power is likely to be flawed too. Algorithmic accountability stories might also, for example, lead on the flawed data underpinning those algorithms, as in Der Spiegel’s ‘Increased Risk‘: the credit reference agency Schufa, it reports, “knows far less about many people than one might think – and yet dares to calculate an exact score.”
Bad data can be used by those in power to mislead the public, so these stories can also be used to factcheck: is a police force underreporting crime, a hurricane-hit country inaccurately reporting deaths, or tests sent are being counted as ‘tests conducted’?
Bad data story ideas can come from the claims of those in power, from hearing about someone who has been through the system and seen its gaps, or from simply scrutinising existing data for problematic features: both this Guardian story on homelessness data being “not fit for purpose”, and this BBC article on concerns over gender pay data came from journalists noticing ‘red flags’ in the data.
They can also lead to follow-up stories where better data is sought through alternative sources, as in this story on homelessness figures by my BBC colleague Dan Wainwright.
A related ‘data problem’ angle is the ‘no data‘ story: often the lack of data on an issue represents a lack of political interest in that issue, or will to address it. One investigation into farm emissions, for example, lists as one of its main findings that “The government only monitors ammonia emissions from the largest intensive poultry and pig farms, completely missing the biggest polluters — beef and dairy farms.”
A strong way to lead ‘no data’ stories is with concerns being raised about the lack of information or transparency. “Medical schools in the UK are ill prepared to deal with the racism and racial harassment experienced by ethnic minority students”, for example, is how one BMJ investigation opens its story.
Vice’s FOI-led story 7 Universities Say They Have ‘Zero’ Reports of Sexual Violence, But the Numbers Don’t Add Up sums up the point of the story with an expert quote:
“The fact that some universities have received no reports doesn’t suggest there is no sexual harassment at that university,” says Jess Asato, the head of policy at Safelives, a UK domestic abuse charity. “It means that they have failed to get to grips with this as an issue that requires full organisational cultural change.”
(Caroline Criado Perez‘s book Invisible Women is an example of an entire book being dedicated to a “data gap” — it’s essential reading for any data journalist not only as an example of the stories that can be told about those, but also because it highlights a range of problems to consider with data you might use for other stories.)
If the missing data was previously published then the story may focus on the decision to stop publishing (The Tampa Bay Times’s ‘Florida medical examiners were releasing coronavirus death data. The state made them stop.‘ is one example), and occasionally it may form the basis of an editorial, such as this one by The Chicago Reporter on the police force shutting down its API.
Occasionally the lack of data may compel a news organisation, journalist or activist to compile their own data — at which point you have a ‘get the data’ story.

Perhaps the most famous examples of these – the Guardian’s The Counted and Washington Post’s Fatal Force — revolve around people killed by law enforcement, and I have written previously about similar examples in Giving a voice to the (literally) voiceless: data journalism and the dead.
Others focus on the activists trying to solve the problem, in what can become part-human interest story: ‘Nobody Accurately Tracks Health Care Workers Lost to COVID-19. So She Stays Up At Night Cataloging the Dead.‘ by ProPublica and this story about Brazilian coders building alternative Covid-19 tallies are two recent examples.
‘Get the data’ stories don’t have to be so ambitious or personal, however. In the early part of the last decade many of the Guardian Datablog‘s earliest stories led with the call to ‘Get the data’ as they opened up datasets that they had found, cleaned, or combined.

Of course, the novelty of merely making data available has faded over the last decade, and some journalists just put their data on GitHub rather than write an article about it.
But if you’ve obtained some interesting data which isn’t available elsewhere — for example through combining multiple datasets, using FOI, or scraping — then there is a lot of value in opening that up to your audience as an act of relationship-building and — in the best cases — community-building.
The point to remember here is that if you do want to build a community the data alone won’t do the work for you: engaging with potential collaborators (for example through organising hackdays) can make it more likely that they build on top of your valuable groundwork.
One more angle: finding stories through, not in, data
Those seven angles are all ways into a story that can be told about data — but there is also another type of data-driven story that doesn’t involve any angle on the data itself.
These are stories where data leads you to something: a person, place or organisation; an event, document or connection, which enables you to find and tell the story around that.
You might call this the ‘single data point‘ or ‘needle in the haystack‘ story. It is often an outlier story, but can also be a story about something especially average or typical.
In a previous blog post I explored some of these techniques, from interviewing individuals connected to a single data point (for example someone running a church in the UK’s least religious city), to seeking an update from an organisation responsible for tackling the numbers you are looking at.
Many investigative stories, for example, use data journalism techniques to help direct their interview and FOI requests, or choose which locations to visit, as they build a bigger picture of a systemic problem.

And explanatory features can use this too: The Washington Post’s Pulitzer-winning 2°C: Beyond the limit uses New Jersey, and then Rhode Island, to tell a story about the impact of global warming because: “it is higher winter temperatures that have made New Jersey and nearby Rhode Island the fastest warming of the Lower 48 states.” In other words, the data provided the direction — and justification — for a choice of case study.
So while those seven angles are useful for sparking ideas and editorial brainstorming when faced with a dataset, they shouldn’t be the limit of your options: any story can benefit from data journalism techniques.

Pingback: Here are the angles journalists use most often to tell the stories in data | Online Journalism Blog
Pingback: Here are the angles journalists use most often to tell the stories in data – Media
Pingback: 3 more angles most often used to tell data stories: explorers, relationships and bad data stories (Online Journalism Blog) | ResearchBuzz: Firehose
Pingback: Presidential Library Explorer, Black Panther, Windows 10, More: Monday ResearchBuzz, September 7, 2020 – ResearchBuzz
Pingback: New Here are the angles journalists use most often to tell the stories in data – Stephen's Lighthouse
Goood blog post