
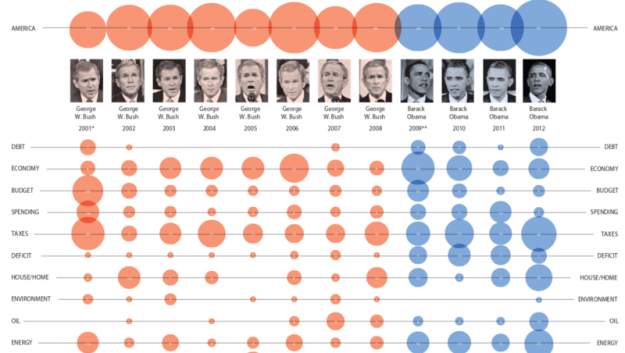
January 2012: The National Post’s graphics team analyzes keywords used in State of the Union addresses by presidents Bush and Obama / Image: © Richard Johnson/The National Post
In a guest post for OJB, Barbara Maseda looks at how the media has used text-as-data to cover State of the Union addresses over the last decade.
State of the Union (SOTU) addresses are amply covered by the media —from traditional news reports and full transcripts, to summaries and highlights. But like other events involving speeches, SOTU addresses are also analyzable using natural language processing (NLP) techniques to identify and extract newsworthy patterns.
Every year, a new speech is added to this small collection of texts, which some newsrooms process to add a fresh angle to the avalanche of coverage.
-
If you’ve ever dug a story out of a pile of text, you can contribute to Barbara’s research by answering a few questions here.

