

1970 sticker album – image by John Cooper
When should you stop buying football stickers? I don’t mean how old should you be – but rather, at what point does the law of diminishing returns mean that it no longer makes sense to buy yet another packet of five stickers?
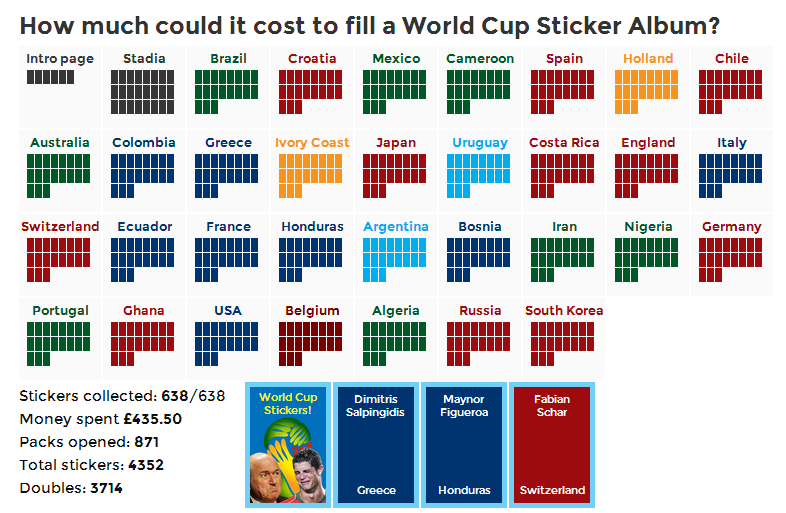
This was the question that struck me after seeing James Offer‘s ‘How much could it cost to fill a World Cup Sticker Album?‘
Sticker albums and collectable cards offer a great opportunity to learn about programming, interactivity and aspects of statistics. Here’s how each might play out in practice:
Statistics: does the company behind the stickers create ‘rare’ ones?
Many buyers think that some stickers are kept artificially rare in order to stimulate demand. So prevalent is the suspicion that it is tackled in this research paper (PDF), which explains, among other things, why it takes 233 packets to get your last three stickers, and why ten friends will all be missing the same sticker 25% of the time.
What a great way to learn about statistical distributions.
Stickers also provide a way to learn about probability. Data journalism outfit Ampp3d and Simon Whitehouse, for example, both used probability to calculate the average cost of filling your album.
Simon Whitehouse‘s calculations are based on this: when I buy my first packet there is a 100% probability that I have none of the stickers; but when I have 200 stickers in my album, that probability is considerably reduced. This is why it takes 233 packets to get your last three stickers.
Programming: write a script to simulate collecting stickers. Then improve it.
Statistics can be quite dry to explain, however, which is why simulations are so much more engaging. They also allow us to explore beyond the average outcomes that statistics predict and show what happens rather than merely describing it.
This makes for a useful introduction to programming. Choosing a language like Python or Javascript you might try to do the following:
- Create an empty variable called ‘album’ and one called ‘swaps’
- Randomly generate five numbers from the range 0-638 (the sticker numbers) – a ‘packet’
- Test if those numbers are in the album – if not, add them. If they are, add them to ‘swaps’.
- Repeat the last two steps until the album is full.
This can then be modified to more closely replicate some of the characteristics of sticker albums and packets – or to record other information:
- The packets cannot contain the same number twice
- All albums come with the same six stickers
- Record the number of stickers in the album and swaps after each ‘packet’
- Record the number of swaps in each ‘packet’
- Run the simulation many times and calculate the outliers and averages
If you’re particularly ambitious you might even have two or more simulations which can ‘swap’ with each other.
The scatterchart below shows the results of one such simulation: it plots the number of stickers in the album (x axis) against a rolling average of the number of swaps in each packet (y axis).

One simulation shows how the rolling ‘swap per new packet’ average changes based on how many stickers are in your album
Clearly the more stickers you have, the more swaps you get – but showing the relationship in detail answers two questions: whether you’re doing well or badly if you get two swaps in that pack of five; and at what point you should probably stop buying any more stickers at all.
Once you have 250 stickers in your album, for example, you can expect two doubles in every packet.
At 350 you can confidently expect three swaps, leaving you only two new stickers.
By the time you get to 400 stickers – with well over 200 empty spaces in your album – it will be common for each new packet to fill only one of those spaces, with the remaining four stickers propping up your doubles pile.
Visualise it
Generating a scatterchart like this – or a histogram – is the territory of visualisation tools, and a final opportunity to learn some more programming. You can generate a histogram with D3 using this tool, for example, or read the relevant documentation on Google Charts, or try the Crossfilter library.
Or you could do what James Offer did, and create something much more gripping…
UPDATE (June 18 2014): More football sticker-inspired data journalism from Ampp3d as they calculate that Mario Balotelli’s Panini sticker joke cost about £1,500. Assuming he didn’t just buy them on eBay. Or Photoshop the whole thing.


Pingback: What you read most on the Online Journalism Blog in 2014 | Online Journalism Blog