
Earlier this month I was interviewed for a feature about data journalism in the Argentina newspaper La Nacion. Here are the full questions and answers, in English, published as part of the FAQ series.
Continue reading
Earlier this month I was interviewed for a feature about data journalism in the Argentina newspaper La Nacion. Here are the full questions and answers, in English, published as part of the FAQ series.
Continue reading
Having outlined the range of ways in which artificial intelligence has been applied to journalistic investigations in a previous post, some clear challenges emerge. In this second part of a forthcoming book chapter, I look at those challenges and other themes: from accuracy and bias to resources and explainability.
Continue reading
Investigative journalists have been among the earliest adopters of artificial intelligence in the newsroom, and pioneered some of its most compelling — and award-winning — applications. In this first part of a draft book chapter, I look at the different branches of AI and how they’ve been used in a range of investigations.
Continue reading
In the summer of last year ProPublica published a major investigation into air pollution in Florida, and its connection to the sugar industry. The story itself, Black Snow, is an inspiring example of scrollytelling — but equally instructive is the methodology article which accompanies it, responding to criticisms from the sugar industry.
Not only does it demonstrate how to respond when large organisations attack a piece of journalism — it also provides a great lesson on the tactics that are adopted by organisations when attacking data-driven stories.
In this post I want to break down the three most common attack tactics, how ProPublica deal with two of those, and how to use the same tactics during planning to ensure your project design isn’t flawed.
Continue readingThis week’s GEN Summit marked a breakthrough moment for artificial intelligence (AI) in the media industry. The topic dominated the agenda of the first two days of the conference, from Facebook’s Antoine Bordes opening keynote to voice AI, bots, monetisation and verification – and it dominated my timeline too.
At times it felt like being at a conference in the 1980s discussing how ‘computers’ could be used in the newsroom, or listening to people talking about the use of mobile phones for journalism in the noughties — in other words, it feels very much like early days. But important days nonetheless.
Ludovic Blecher‘s slide on the AI-related projects that received Google Digital News Initiative funding illustrated the problem best, with proposals counted in categories as specific as ‘personalisation’ and as vague as ‘hyperlocal’.
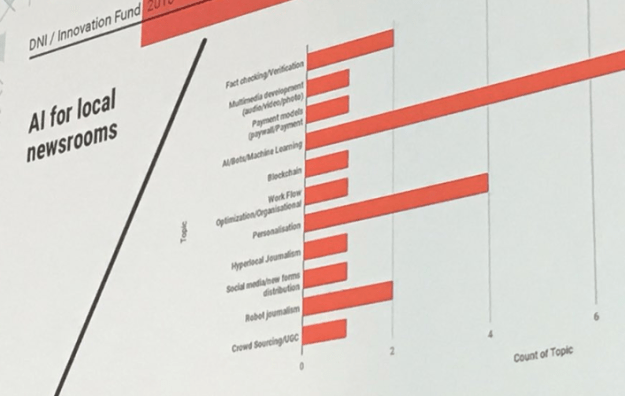
Image by Marc Springer
Digging deeper, then, here are some of the most concrete points I took away from Lisbon — and what journalists and publishers can take from those.

Photo: Pixabay
Women represent 49.5% of the world’s population, but they do not have a corresponding public, political and social influence. In recent years, more and more women have raised their voices, making society aware of their challenges — data journalists included. To commemorate International Women’s Day, Carla Pedret presents a list of data journalism projects that detail the sacrifices, injustices and prejudices that women still have to face in the 21st century.

Image by Carla Pedret©
Podcasts are a great way to listen to stories on the move, be entertained, or keep up with developments in a particular field. However, have you ever thought about using them to learn data journalism?
In this list, I have pulled together some of the best podcasts about data. Some are specifically about data journalism, whereas others approach data from another perspective.
Continue reading

The list already boasts journalists from some of the leading data journalism projects in Latin America
A new data journalism mailing list for Spanish speakers has been launched by The National Institute for Computer-Assisted Reporting (NICAR) and its parent organisation, Investigative Reporters and Editors (IRE), reports Barbara Maseda.
NICAR-ESP-L, as it is called, seeks to be the Spanish version of NICAR-L, a mailing list in English that has been active for over 20 years. Continue reading

Una nueva lista de correos en español dedicada al periodismo de datos ha sido puesta en marcha por el Instituto Nacional de Periodismo Asistido por Computadora (NICAR) y su organización madre, Reporteros y Editores de Investigación (IRE), radicada en la Universidad de Missouri, Estados Unidos.
NICAR-ESP-L es el nombre de este servicio que busca ser una versión en español de NICAR-L, una lista de correos en inglés que ya acumula más de 20 años de actividad.
NICAR-L tiene actualmente más de 2,300 miembros y un archivo de más de 78,000 mensajes desde su fundación en 1994, según el comunicado de prensa que anuncia el lanzamiento.
La versión en español, al igual que la inglesa, está abierta a suscripción para todos los interesados, sin importar si son miembros de IRE o no, añade el comunicado.
Looking across the comments in the first discussion of the EJC’s data journalism MOOC it struck me that some pieces of work in the field come up again and again. I thought I’d pull those together quickly here and ask: is this the beginnings of a ‘canon’ in data journalism? And what should such a canon include? Stick with me past the first obvious examples…
These examples of early data visualisation are so well-known now that one book proposal I recently saw specified that it would not talk about them. I’m talking of course about… Continue reading
