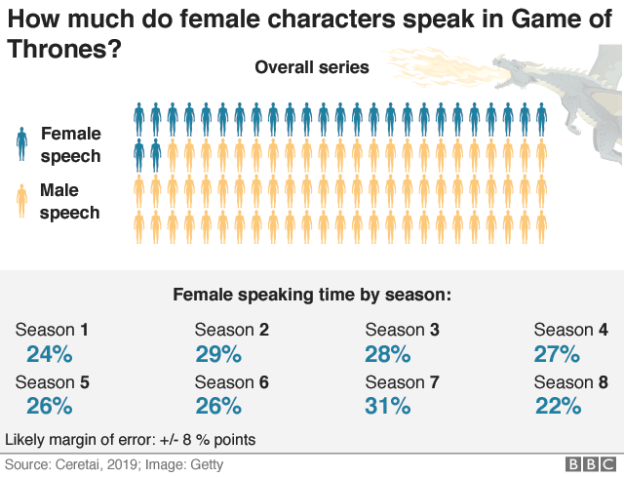
The BBC’s chart mentions a margin of error
There’s a story out this week on the BBC website about dialogue and gender in Game of Thrones. It uses data generated by artificial intelligence (AI) — specifically, machine learning — and it’s a good example of some of the challenges that journalists are increasingly going to face as they come to deal with more and more algorithmically-generated data.
Information and decisions generated by AI are qualitatively different from the sort of data you might find in an official report, but journalists may fall back on treating data as inherently factual.
Here, then, are some of the ways the article dealt with that — and what else we can do as journalists to adapt.
Margins of error: journalism doesn’t like vagueness
The story draws on data from an external organisation, Ceretai, which “uses machine learning to analyse diversity in popular culture.” The organisation claims to have created an algorithm which “has learned to identify the difference between male and female voices in video and provides the speaking time lengths in seconds and percentages per gender.”
Crucially, the piece notes that:
“Like most automatic systems, it doesn’t make the right decision every time. The accuracy of this algorithm is about 85%, so figures could be slightly higher or lower than reported.”
And this is the first problem. Continue reading →