
Looking across the comments in the first discussion of the EJC’s data journalism MOOC it struck me that some pieces of work in the field come up again and again. I thought I’d pull those together quickly here and ask: is this the beginnings of a ‘canon’ in data journalism? And what should such a canon include? Stick with me past the first obvious examples…
Early data vis
These examples of early data visualisation are so well-known now that one book proposal I recently saw specified that it would not talk about them. I’m talking of course about…
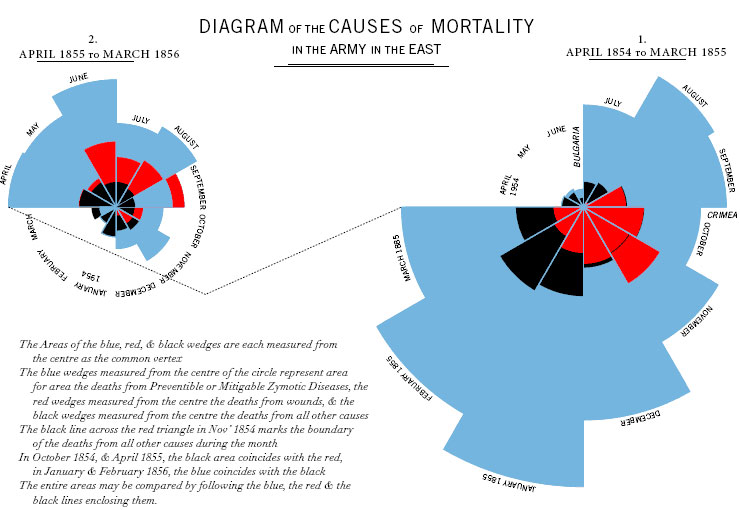
Florence Nightingale and Crimean War deaths
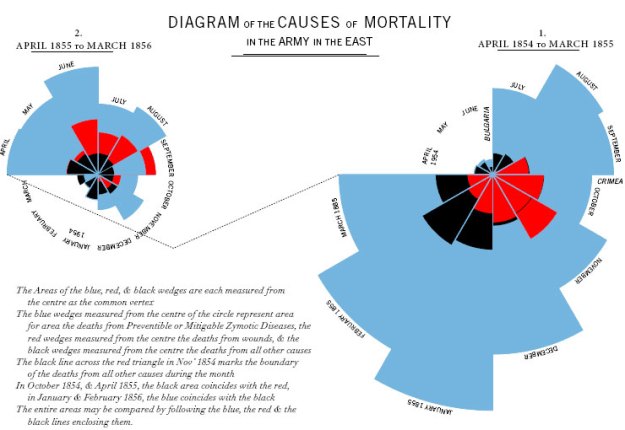
Minard and Napoleon’s army

Jon Snow’s cholera map

Minard and Nightingale both manage to tell tragedies in a chart, but where Nightingale challenges an assumption, Minard’s is an actual narrative. Put another way: Nightingale performs the journalist’s role of telling truth to power; Minard tells a cracking story. Both are more effective than mere words would be.
Snow’s map doesn’t tell a story anywhere near as clearly, but it’s the story behind and around it that matters. The map actually played a marginal role in Snow’s data journalism, and the more interesting aspect is how shoe leather and a sort of ‘citizen journalism’ or ‘citizen science’ (a local priest) played a much larger role. Steven Johnson’s The Ghost Map tells the story.
Data on the front page (The Guardian, Llloyds List)


Many newspapers printed tables prominently in the 19th century. Why in the canon? It serves to remind us that we’re not quite as innovative as we think we are.
The Detroit Riots and Philip Meyer

The birth of modern data journalism comes with ‘Computer Assisted Reporting’ (CAR) and particularly the work of Philip Meyer from the late 1960s on.
Meyer applied social science methods to journalism in order to test claims about the reasons for massive civil disturbance and with his book Precision Journalism inspired a generation of journalists in the US and beyond.
It also provided the inspiration for another potentially canonical piece of data journalism 45 years later: Reading the Riots, which saw a similar partnership of news organisation (The Guardian) with academic researchers (LSE). You can read the LSE study here (PDF).
Mashing and mapping: ChicagoCrime.org

Adrian Holovaty was the Meyer of the 2000s. Taking crime data published by Chicago police, and ‘mashing’ (combining) it with Google Maps, he made it possible for any user to check out crime patterns in any area. Like Meyer, it inspired a generation.
What made this different to the CAR that went before was two things: firstly, the user could choose where to look, not just the journalist. Secondly, the data was live and automatically updated. It didn’t sit on a reporter’s computer – or a university mainframe. It was networked.
Letting users do interesting things with your data: APIs at the BBC and beyond
What Holovaty did – combining data from more than one source – is much easier if you have an API to work with (he didn’t).
Twitter’s API, for example, allows you to ‘fetch’ the latest tweets from your friends, or around a particular location or hashtag. Google Maps’ API allows you to ‘fetch’ a map around a particular location, and place markers or routes on it. You can combine the two to fetch tweets and place them on a map.
In 2009 the New York Times and Guardian both attracted a lot of attention when they launched APIs which allowed anyone with coding knowledge to build applications with their data (articles, but also political information) and do interesting things, helping drive new traffic to neglected archive material and helping test the market for mobile apps.
But 4 years earlier the BBC had been opening up its own content in a similar way with the Backstage project. It influenced Adrian Holovaty to set up something similar at The Washington Post – PostRemix.
APIs are likely to be increasingly important in connecting stories with readers through social media. Witness ProPublica’s use of the Facebook API, for example to create a news app around education data, or PBS Frontline’s use of ProPublica’s Forensics API to map death investigations.
Animated data: Gapminder and Hans Rosling
Rosling’s TED video from 2007 accrued so many views online that the BBC commissioned him to recreate it for a TV series on statistics. It proved that numbers and charts could attract a mass audience – but it also proves that you sometimes need a narrator to make a story.
Rosling is a master storyteller, and without him the animations wouldn’t have nearly the same impact. To watch him at work is a masterclass in turning numbers into narratives.
‘Open Data’ journalism: MySociety and its children

MySociety won an award for their work on the empty homes investigation – and were nominated for two others
Before Holovaty and Rosling, and before the term open data was used by journalists, a small group of developers gathered to combine their skills to help create a more informed electorate.
Their ideas were to perform many of the roles that journalists might claim they perform:
- Providing a platform for citizens to communicate with their elected representatives (FaxYourMP/WriteToThem; FixMyStreet; ReportEmptyHomes)
- …And for representatives to communicate with citizens (HearFromYourMP);
- Making it possible for citizens to see how their representatives had voted (TheyWorkForYou) and what they stand for (Democracy Club).
- And empowering citizens to hold power to account (WhatDoTheyKnow)
You can argue all you like about applying the term ‘journalism’ to their work (they worked with Channel 4 News on the 2005 election and were nominated for an Emmy and BAFTA for their work on The Great British Property Scandal), but it has undoubtedly had both a major impact on the environment data journalists work in, and influenced data journalism publishing.
When a site like ProPublica makes tools out of its data, or the Houston Chronicle allows users to email their elected representative as part of a data-driven interactive, they are using functionality that MySociety pioneered a decade ago.
And MySociety inspired dozens of similar sites across the world, including direct clones in Ireland, Norway, Kosovo, Brazil, Spain, Hungary, Uruguay, Australia, Bosnia, the Czech Republic, Canada, Israel, Tunisia and Romania.
AskTheEU – a European-level FOI site – is based on MySociety technology. In Kenya, Mzalendo uses it to track their Parliament, in Ghana Odekro uses it too and in Nigeria, Zimbabwe and South Africa respectively ShineYourEye, Kuvakazim and the People’s Assembly website all use it too. They use their technology in the Philippines, Malaysia, and Switzerland.
In Chile they collaborated with Ciudadano Inteligente to expose MPs’ conflicts of interest. And projects like Kildare Street in Ireland, and TheyWorkForYou.co.nz in New Zealand took their cue from MySociety projects.
‘Open’ data journalism: The Guardian Datablog
I’d considered including this in the original list but held back until Simon Rogers also mentioned it in the comments. It has a good case for being included for a number of reasons: firstly, it has been widely imitated by organisations from ProPublica and La Nacion to the Texas Tribune and Wales Online.
‘Showing your sums’, as I wrote in 2009 when The Guardian launched its datablog, has become a key part of building trust in reporting.
Secondly, it proved a business point about data journalism: people spend time reading it. The last time I asked, posts on the datablog had a dwell time around four times higher than the site average (and the Texas Tribune sees a majority of its traffic coming through their databases).
Finally, however, and perhaps most importantly, it showed how to involve users in the process.
The associated Flickr pool, for example, has been a source of leads and visual treatments that otherwise wouldn’t have found a way into the organisation, while data experts like Tony Hirst and Adrian Short have contributed their skills through the datastore.
Big data: Wikileaks

Sources of Wikileaks cables. Image Source: Zero Geography
Not one story but hundreds. Wikileaks is canonical because it forced many news organisations to skill up in order to deal with the tranche of data they were getting. In many places that meant a quantitative shift from spreadsheet software to SQL databases.
It also brought specialist reporters and ‘the geeks’ together at an organisational level, each party needing the other. One piece of research even concluded that:
“WikiLeaks’ lasting impact on journalism has been on forcing the profession to confront its own definitional crisis; drawing awareness to persistent legal issues facing journalists in the digital age; and in revealing the complexity of global information flows.”
Bigger data: Offshore leaks

Image: ICIJ
Many people will argue whether Wikileaks was really ‘big data’. Offshore Leaks was 160 times bigger, far less structured, and resulted in a similar global spread of stories on the use of tax havens.
In terms of journalism it made it clear that we hadn’t seen anything yet.
Your local canon? MPs’ expenses and crowdsourcing

MPs’ expenses – image from Telegraph
I hesitate to include the MPs’ expenses scandal in this list because it is a UK-based story. It had an enormous impact on journalists’ perceptions and take up of data journalism in the UK, but I’m never sure how much impact The Telegraph’s incredible six-week period of dominance had further afield.
The Guardian’s subsequent crowdsourcing of the publicly released expenses certainly made waves (while far from the first time data had been crowdsourced), however, and perhaps it deserves a place because of that. I’d be interested in perceptions from outside the UK.
I’d also be interested in the stories you consider canonical in your own country or region. Should we include The color of money? The New York Times Dialect quiz? A data-driven media business like Skift?
Over to you.
Update 1: Canonical in Brazil? Diaros Secretos

From the comments, Träsel nominates Diários Secretos as particularly influential in Brazil. You can read more about it here (in Portuguese) and the wider impact here (in English), and there’s a YouTube channel here.
Mapping on the front page: The Times in 1806

In 1806 The Times ran a map to illustrate a murder on its front page
Suggested in the comments by Felipe Saldanha, I don’t think this qualifies as data journalism as such because there’s no structured data behind it. That said, I just like the image and the idea that mapping a news event has a 200 year-plus history.

{kind=link}
{kind=link}
In Brazil, the canon would be “Diários Secretos”, a series published by Gazeta do Povo, a newspaper:
http://www.gazetadopovo.com.br/vidapublica/diariossecretos/
Gazeta do Povo earned a Prêmio Esso, the brazilian Pulitzer, for this reporting effort.
There is an explanation in English here:
http://www.rpctv.com.br/diariossecretos-english/
Thanks – added!
Nice!
The reason it was influential, in my opinion, is the scope of the reporting: the team painstakingly transcribed hundreds of proceedings — which were photocopied from secret paper archives — from the State Congress to spreadsheets. The database was published for anyone to search, in the hopes that citizens would spot offenses by the representatives. A series of news articles was published on the newspaper and aired on TV. The result was the toppling of the House president and some other representatives, because they were caught employing family members. And they are still publishing news based on this effort.
So we’ve got database creation, data analysis, crowdsourcing, multimedia… It is a very well-rounded data journalism example, in my opinion.
Another DDJ piece that could be in the brazilian canon is Basômetro:
http://estadaodados.com/basometro/
This was the first material created by Estadão Dados, which was the first dedicated DDJ team in Brazil. This news app aggregates data from every National Congress vote since 2011. The goal is to show wether each specific congressman has voted for or against the Federal Government (i.e., the president of Brazil). As a result, the audience may check how much support (or “base”, hence Basômetro) the Executive has had from the Legislative over the years, how their representatives have behaved, and where each party stands (and how they change position).
There was even a book published with articles by political scientists who used the Basômetro as a tool for analysis.
Good call. Also makes me wonder whether They Work For You in the UK should be mentioned, as it performed a similar task and inspired sites in Ireland, New Zealand and Australia. More broadly the team behind it, MySociety, built sites which influenced others too, like AskTheEU. I wonder whether Basometro were also influenced.
Pingback: hotel, money, niceIs there a 'canon' of data journalism? Comment call! | Online ... | Technology News
Many branches of #ddj. Examples of #dataviz and longform are varied and accessible. The canon could be the internet itself.
Personally, I like the virus map you have as an example, since I like #mapping and #dataviz.
Such a great idea to do this post Paul. It’s also interesting because it’s the stories that stand up to histroy that should make the list (which we might not realise at the time). I would make the case for a couple of others:
Reading the Riots – OK, so I was involved in this and although heavily influenced by Meyer, it deserves its own entry. The compilation of the biggest criminal database in journalistic history (1,000) records is a big deal.
Dollars for Docs by Propublica – the model use of public data to make a passionate case.
What about the Snowden docs? Don’t they make the cut?
I considered all three, funnily enough! I was going to mention Reading the Riots in connection with Meyer. Significant, yes – but did it have a wider impact? That was my test. Dollars for Docs likewise – I wasn’t sure if that was just something that impressed me, or something that had a wider impact.
Snowden was difficult – it’s certainly one of the biggest stories of the age, but in my opinion its biggest impact has been the documents, not the data. I’d be open to persuasion on this one – are there particular Snowden stories which were based on data that you think will be historically significant?
You may be right on Snowden, and with Wikileaks I would argue it was the Iraq and Afghanistan releases that had the biggest effect on DDJ, even if the cables were a bigger story.
Now I’m going to add something cheeky: what about the Guardian Datablog? This was arguably the first data journalism site ever created by a national news organisation, a model which has obviously been copied since.
I did think about the datablog too, but couldn’t be certain how early it was. On that front I should also consider some of the first APIs – the BBC’s Backstage project predated those of the NYT etc.
Pingback: Is there a 'canon' of data journalism? Comment call! | Online ... | Technical innovationsTechnical innovations
In the broadest sense, the word ‘canon’ refers to the works of a writer which the general public consider authentic. Zimbabwe had not been left out of the Digital Revolution which one would presume is still at an infancy stage globally.
Over the past year, a character on Facebook called ‘Baba Jukwa,” has had people believing his posts on matters to do with the Zim government. At one point, the faceless character warned about impending disaster for one government official, Edward Chindori-Chininga and within a short space the official was involved in an ‘accident’ that claimed his life.
It is alleged that the character has been unmasked. [for more information, google up “Baba Jukwa”]
The Internet & mobile phones have contributed immensely to the politics of Zimbabwe. Wikileaks made sure that they were no sacred cows globally, even in Zimbabwe, exposing high ranking government officials. Critiques have more often dismissed the Baba Jukwa character as a plagiarist who lifted stories on wikileaks.
It would be unfair to to turn a blind eye on the contribution made by Facebook to help such pseudo-characters gunner such followers as well as keep government officials on their feet.
Thanks – yes, canon does have that meaning but it also has a meaning of a collection “the list of works considered to be permanently established as being of the highest quality – ‘Hopkins was firmly established in the canon of English poetry'”.
I’m not sure how we could put Facebook specifically within data journalism?
You could add the People’s Assembly in South Africa (http://www.pa.org.za) to your list of My Society-inspired/partner projects 🙂
I did!
Fellow DDJ MOOC-er here, interesting post! It’s a bit unconventional, perhaps, but I wonder if some of the work by xkcd could be considered as part of a data journalism canon… you may have seen the epic infographic circulating a while back about money, for example: http://xkcd.com/980/ Coming from what is normally a simple webcomic, it was quite an ambitious and impressive project!
Interesting call! My test is whether it’s has a wider influence on data journalism practice. I’m not sure a specific xkcd strip would meet that test – but I’m open to persuasion with examples!
and who by, why and how that FB data would be scraped, unless the data on security databases are leaked one day.
Hi Rogers.
I do appreciate the way Paul brought in the different uses of data, well aware that the different audiences that we do address at times have a remarkable knowledge of what we seems to explain to them. Having a list is very important for reference each time we have a related event of such nature.
Dear Mr. Bradshaw, I wonder if the illustration of the Blight murder at front page of The Times of April 7, 1806 could be considered part of the canon of data journalism. What do you think? (More information at this book: http://goo.gl/S0LHqt)
Interesting one – ultimately it’s a floorplan so although it’s ‘mapping’ is it really based on structured data? I’d say not. Nice suggestion, though.
Hi Mr. Bradshaw, I tried to comment here yesterday, but for some reason it appears not to have been submited.
I’d like to know if you think that the graphic of Blight’s murder at edition of April 7, 1806 of The Times could be considered part of canon of data journalism. More information in this book: http://goo.gl/S0LHqt
It was held up for moderation. Now approved. I’ve added an image to the post.
Pingback: What you read most on the Online Journalism Blog in 2014 | Online Journalism Blog
Pingback: FAQ: 24 questions about data journalism | Online Journalism Blog
Pingback: We need a Data Journalism Archive. Before it becomes just another 404 error | Simon Rogers