
When you’ve converted data from a PDF to a spreadsheet it’s not uncommon for text to end up being split across multiple rows, like this: 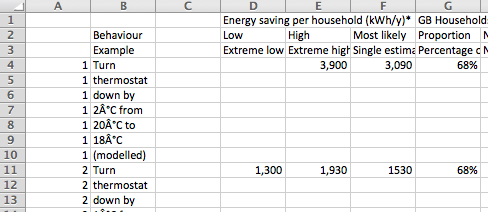 In this post I’ll explain how you can use Open Refine to quickly clean the data up so that the text is put back together and you have a single row for each entry.
In this post I’ll explain how you can use Open Refine to quickly clean the data up so that the text is put back together and you have a single row for each entry.
- If you haven’t used Open Refine before read this introductory post first. You can also find all my posts on Open Refine here.
- Do not use it in Internet Explorer – instead either set your default browser to Chrome or Firefox, or copy and paste the address generated by Refine (http://127.0.0.1:3333/) into one of those browsers.
The example above was converted from a PDF table (using the free tool Tabula) by a student of mine at Birmingham City University, Cristian Giulietti. You can download it here. The resulting story is linked at the end.
Step 1: Headings across multiple rows
Before sorting out the text across multiple rows you may also have headings across multiple rows (as in the example shown above). These can be combined easily at the import stage, which I explain in a separate post.
Step 2: Blank down
With the headings cleaned up you should have a starting point that looks something like this:  Our biggest friend here is the column containing a number for each row – 1, 2, and so on (called simply ‘Column‘ above). If you don’t have a column like this then you can identify an equivalent to it. For example, a column which always contains numbers (e.g. High extreme… in the example above). As this doesn’t need blanking down, you wouldn’t need to follow this step – but you would need to make sure it was in the first column (see below). Select that column of data and click on the dropdown menu at the top. Select Edit cells > Blank down.
Our biggest friend here is the column containing a number for each row – 1, 2, and so on (called simply ‘Column‘ above). If you don’t have a column like this then you can identify an equivalent to it. For example, a column which always contains numbers (e.g. High extreme… in the example above). As this doesn’t need blanking down, you wouldn’t need to follow this step – but you would need to make sure it was in the first column (see below). Select that column of data and click on the dropdown menu at the top. Select Edit cells > Blank down.

This will transform the column so instead of the number being repeated it will only appear once, with all subsequent repetitions underneath transformed into blank entries. It doesn’t matter if a number is used again later in the data – it’s only the first in each series which is affected. So, for example, if there is a series of rows with ‘1’ in them early on, this will keep the first but turn all the rest into blanks, until it hits a different number. If ‘1’ then appears later in the data it will still be kept, but again any further ‘1’s directly following it will be ‘blanked down’ until it hits a different entry. The result will look like this. Note that Open Refine’s own row numbering – in the All column – changes to reflect the cells now blanked out in the first column of your data:  Note: it is important that the column you blank down should be the first column in your data, because Open Refine will use this to order your data. If you were doing this on data where it wasn’t the first column, you’d have to move it there first, either in Excel or Google Spreadsheets or Refine, which you can do by selecting Edit column > Move column to beginning.
Note: it is important that the column you blank down should be the first column in your data, because Open Refine will use this to order your data. If you were doing this on data where it wasn’t the first column, you’d have to move it there first, either in Excel or Google Spreadsheets or Refine, which you can do by selecting Edit column > Move column to beginning. 
Step 3: Join the pesky split cells
With those cells blanked down it will now be possible to join the problematic text cells. To do this, select the column with the annoying split headings (‘Behaviour example‘ in the example above) and select Edit cells > join multi-valued cells.

A window appears asking you for a separator:

Delete anything in the box – you don’t need a separator (which would be placed between the contents of each cell); you just want to join the text. Click OK. This should now give you proper ‘behaviours’. Because we blanked down the numbers in the first column Refine knows which cells relate to each other, and how to merge them:

That’s it! You can now export the project as a spreadsheet (see below). But first…
Bonus step: cleaning numbers
This extra step is nothing to do with our main problem, but is worth mentioning in case you want to finish the cleaning of this data in particular. Some of the numbers are not recognised as numbers – Refine thinks they are text because they contain commas. You can tell this because Refine shows numbers as green and right-aligned, while text is shown as black and left aligned (as would be the case in Excel):  There are ways of cleaning this up column-by-column in Refine… (if you’re interested it’s Edit cells > Transform… and the expression value.replace(“,”,””).toNumber() to replace the commas and convert the result to a number) …but actually Excel will interpret these as numbers anyway. So, to get this into Excel, export from Open Refine by selecting the Export button in the upper right corner and then either Comma-separated value or Excel – either format will work in Excel.
There are ways of cleaning this up column-by-column in Refine… (if you’re interested it’s Edit cells > Transform… and the expression value.replace(“,”,””).toNumber() to replace the commas and convert the result to a number) …but actually Excel will interpret these as numbers anyway. So, to get this into Excel, export from Open Refine by selecting the Export button in the upper right corner and then either Comma-separated value or Excel – either format will work in Excel.  Once in Excel you can tell it sees these as numbers because they are right-aligned, while text is left-aligned:
Once in Excel you can tell it sees these as numbers because they are right-aligned, while text is left-aligned:  And here’s the story that came from that data, by the way (using a second source of data for context).
And here’s the story that came from that data, by the way (using a second source of data for context).

Pingback: What you read most on the Online Journalism Blog in 2014 | Online Journalism Blog
Awesome app. My sheet was sorted in minutes for row merger.
Thanks for the walkthrough, this helped me create my first transformation on OpenRefine.