

Having outlined the range of ways in which artificial intelligence has been applied to journalistic investigations in a previous post, some clear challenges emerge. In this second part of a forthcoming book chapter, I look at those challenges and other themes: from accuracy and bias to resources and explainability.
The most basic challenge facing investigative journalists wanting to apply artificial intelligence is practicality: not only do AI technologies such as machine learning require a certain combination of skill sets and the time and resources to bring those together, but also the availability of a sufficient quality and quantity of data to train models (Dorr, 2015; Stray, 2019) and the computational infrastructure to run them.
These practical challenges sometimes lead newsrooms to outsource part or all of projects involving AI, or partner with external parties. The New York Times’s investigation into bomb craters in Gaza, for example, used a third-party object detection platform, partly because of the computing power required.
“Satellite images can easily surpass several hundred megabytes or even a couple gigabytes,” reporter Ishaan Jhaveri explained. “Any local development work on satellite images would naturally be clunky and time-consuming.”
And while the International Consortium of Investigative Journalists “doesn’t outsource the work of training data to ensure accuracy”, they did use a machine learning tool called Snorkel to help classify text and images, while the open source intelligence platform Bellingcat has used the Ship Detection Tool — a machine learning algorithm run on Google Earth Engine — in its investigations.
Information security, copyright and data protection
The use of third party tools such as Google’s Pinpoint, Cloud Document AI and Gemini, and OpenAI’s ChatGPT, raises issues around independence and power, and — where editorial information is fed into such tools — information security, copyright, privacy and data protection. Many organisations’ guidelines, for example, prohibit “entering confidential information, trade secrets, or personal data into AI tools.”
In some cases manual methods of classification may be quicker than an automated approach: most of the spy planes identified in Peter Aldhous’s story for BuzzFeed, for example, could have been identified through data analysis while one analysis of investigative journalism projects concludes that “many document sets in journalism are simply too small to benefit from AI methods”.
Alternative, quicker, approaches to machine learning listed by the New York Times’s Rachel Shorey include: “making a collection of text easily searchable; asking a subject area expert what they actually care about and building a simple filter or keyword alert; [and] using standard statistical sampling techniques.”
In some projects, however, the time and cost of development might be amortized over multiple stories, such as the Norwegian factchecking outlet Faktisk Verifiserbar, who worked with AI researchers to develop a language identification tool and a tank identification tool.
Accuracy: training models and human oversight
The quality and quantity of data used to train AI models has a direct impact on the quality of the results obtained — a principle summed up in the mantra ‘Garbage In Garbage Out’ (GIGO). This includes the classification of training data: in the Pulitzer-winning investigation “Missing in Chicago” a machine learning tool called Judy was used to classify police misconduct records in the city, helping to identify 54 allegations related to missing persons in just four years. But crucially, the training data for the tool was created by 200 volunteer workers from the community, who manually labelled the records.
“Even if they didn’t come in with the language to describe a machine learning algorithm, they had lived experience that an outsourced data labeler could not,” data director Trina Reynolds-Tyler said of the project, recommending that machine learning projects “understand the value of embedding in the community they are reporting on, and grounding their data work in real places and real people.”
100% accuracy is rarely achieved in a model — indeed, an extremely high accuracy can be a sign of ‘overfitting’, whereby a model fits its training data too closely and so performs poorly when tested on other data. An ‘overfit’ model has often become too complex, perhaps because it has been overtrained and/or because irrelevant ‘noise’ in the data is shaping the algorithm.
An ‘underfit’ model, in contrast, performs poorly on both training data and testing data, often as a result of a simple model based on too little data and/or too little training. A successful algorithm will be neither.
Feature engineering will also need to be adjusted to shape the accuracy of any machine learning model: this involves choosing, or extracting, the facets of the data that the model will use.
Some features may have to be extracted from existing data, such as converting or splitting text data into categorical data, or using two figures from the data to calculate a new third measure. Specialist knowledge of the field can be key to choosing the most relevant features (as demonstrated by ProPublica’s modelling of Ebola outbreaks).
As a result of these issues human oversight is key in accurate use of AI, and a recurring theme both in news organisations’ guidelines on the use of AI, and in concerns expressed by journalists.
Peter Aldhous’s experience with using the technology to identify spy planes reinforces this:
“Its classifications need to be ground-truthed. I saw [the model] as a quick screen for interesting planes, which then required extensive reporting with public records and interviews.”
For those models used over a longer timescale, or those involving predictions, oversight takes on an extra dimension: when the Atlanta Journal-Constitution created a model in 2015 to forecast whether bills would pass the Georgia legislature, for example, the performance of the model was regularly reviewed in public.
Such transparency and accountability is encouraged in many guidelines (see also this review), both as a further protection against errors and as a means of maintaining trust. But this is problematic: “Algorithms challenge this goal,” guidance from the Catalan Press Council notes, “because of the opacity involved in the way they make automated decisions.”
Interpretability and explainability
The opacity involved in automated decisions can also present problems for explaining or even understanding the results of AI models. These two qualities — explainability and interpretability — are separate: a model might be explainable (you can explain what it does and why it arrives at a certain output) but not interpretable (you do not know how it does that).
Explainability and interpretability can determine the choice of technology: many investigations opt for a ‘decision tree’ or ‘random forest’ algorithm over more powerful ‘neural network’ or ‘deep learning’ approaches because of interpretability (they also don’t need as much data).
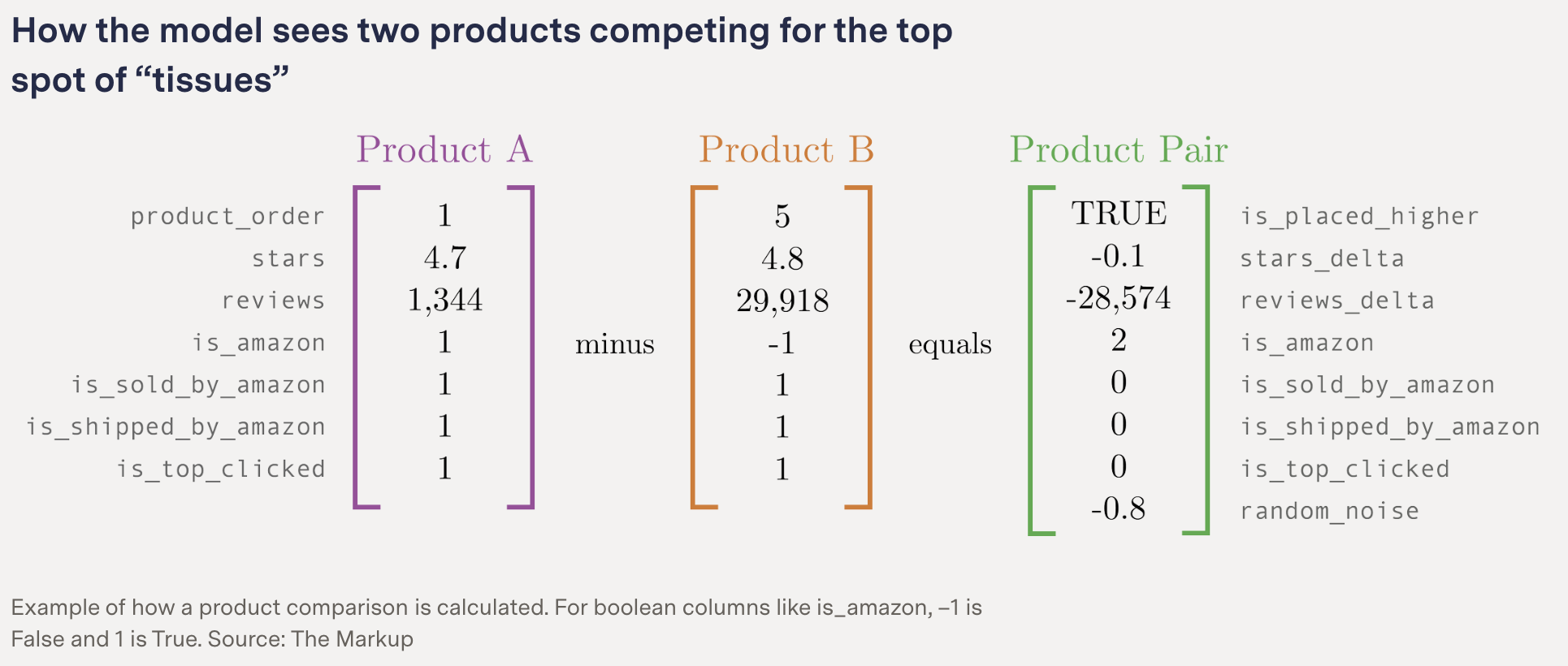
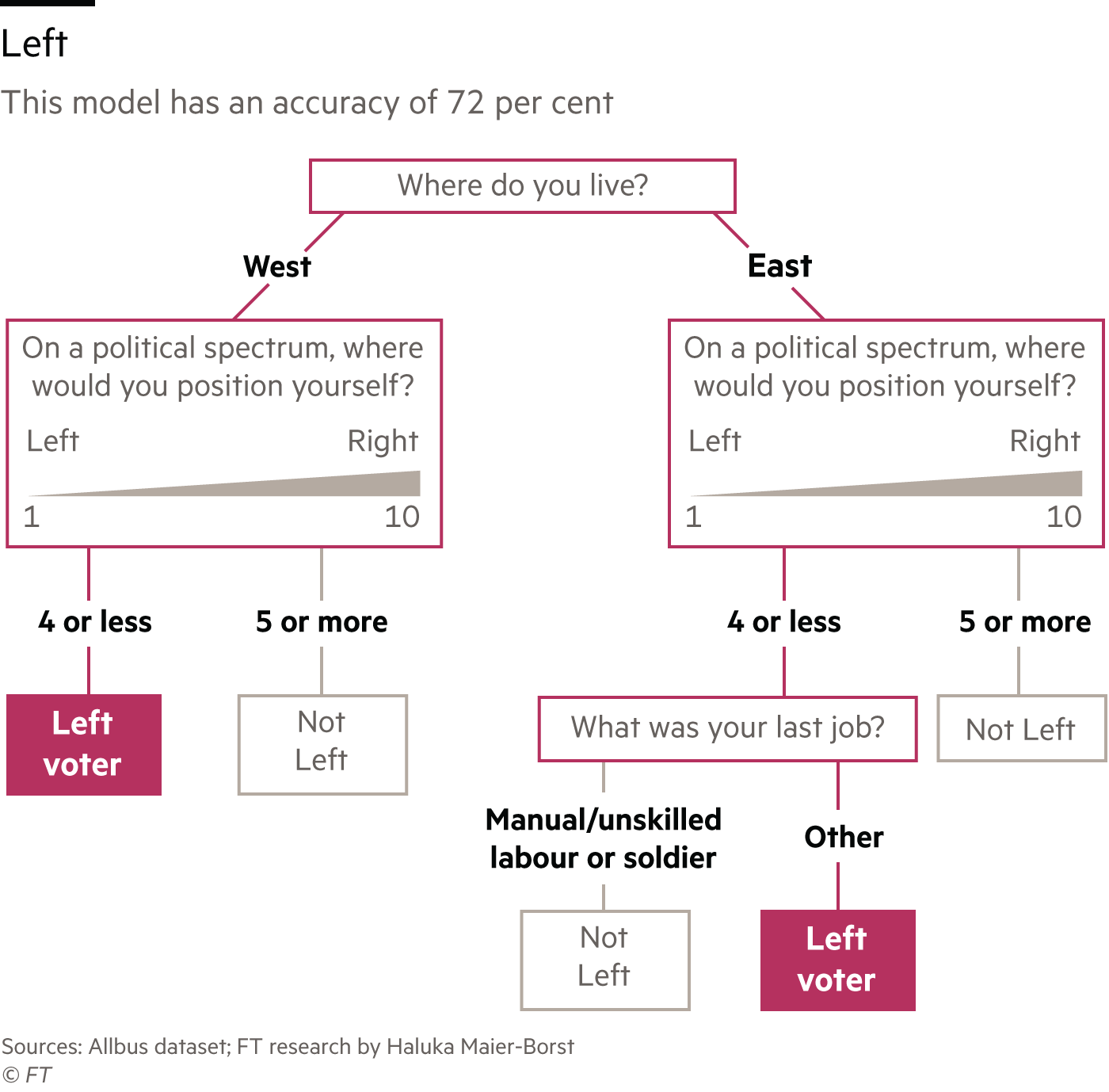
One ProPublica investigation into political emails, for example, used a decision tree-based algorithm “because [they] produce a human-readable tree of partitions of the data”, and one FT story analysing how closely particular voters’ characteristics correlate with voting behaviour used it as the basis for visualising a series of branching models, with accuracies ranging from 56 to 72 percent. The Markup’s investigation into Amazon’s treatment of its own brands in search results used a random forest algorithm — which combines multiple decision trees — to compare products and “control for which features led to higher placement”.
Regulations such as the European GDPR now require AI systems to include explanations, and so even less interpretable neural networks might incorporate an explanation in the form of a Local Interpretable Model-Agnostic Explanation (LIME). This works by “treating the [model] as a black box, and probing it with different random input values to create a data set from which the interpretable model can be built” (Russell, Norvig & Chang, 2022), a process analogous to that used within algorithmic accountability projects. The audio deepfake detection tool VerificAudio, for example, indicates to journalists which audio attributes were a factor in the resulting score.
Explainability might also be considered as part of prompt engineering when using generative AI tools: simply adding “Let’s think step by step” to a prompt, for example, can result in a response that offers “some visibility for people to understand how the model arrived at the final output it did”.
A further editorial challenge lies in the way that machine learning models produce estimates or likelihoods, rather than specific figures. This is analogous to the challenge of reporting on predictions or data where there is a margin of error: journalists must be careful to communicate the uncertainty in the data accurately. This happens in a number of ways: through qualifying language (“about a quarter”, “estimated to be”) and attribution (“according to the algorithm used for the analysis”), or through further manual classification of any sample categorised by the algorithm as relevant to the investigation.
Even confirmation means that false negatives (matches that should have been identified but weren’t) will be missed, and so qualified language will still be needed to report that the real figure is ‘likely to be higher’.
Diversity, bias and fairness
Artificial intelligence’s tendency towards bias, and lack of diversity, is often the focus of algorithmic accountability reporting — but it also presents a challenge for reporters using the technology itself. Categories of bias identified in one paper include:
- Biased labelling;
- Biased features (also known as ‘curation bias’);
- A biased objective;
- Homogenisation bias (where the output from one model is used for future models);
- Active bias (where data is made up, e.g. fake news); and
- Unanticipated machine decisions (where a lack of context leads to “untenable answers”)
(For a much longer list, see this paper)
Bias is also a consideration when collecting data — minorities are typically underrepresented in datasets, leading to selection bias and lower accuracy in relation to those groups — and in testing (if a model is not tested with diverse inputs or monitored for bias).
Large language models, for example, have much poorer performance with regard to non-English languages and non-Western contexts, as these represent a much smaller part of both the training data and of testing, as does material authored by women. For those creating their own models, there is a similar lower availability of labelled datasets and research in those languages and contexts (Adelani, 2022; de-Lima-Santos, Yeung & Dodds, 2024).
Identifying and measuring these biases is an important consideration in ensuring “fairness” in an algorithm. This concept can involve multiple criteria which can conflict with each other, from individual and group fairness (being treated similarly to other individuals and groups), to equal outcome (there should be parity in the outcomes for different demographic groups), opportunity (parity regardless of demographic) and impact (both positive and negative). Open source toolkits developed to support fairness assessment in AI include IBM’s AI Fairness 360 toolkit, Microsoft’s Fairlearn and Amazon’s SageMaker Clarify.
With third party generative AI tools journalists typically have no control over the training material that has been used, or the way that the model was trained. Guidelines produced by Birmingham City University’s Sir Lenny Henry Centre for Media Diversity therefore advise:
“Journalists should explicitly seek, through their prompts, for Generative AI to draw on source material written and/or owned by different demographics. Where this is not possible journalists should use prompts to obtain lists of experts and recognised commentators on specific issues from different backgrounds. Going to the original work of these experts and commentators directly can complement any material created by Generative AI and address possible biases.”
Even when it comes to custom machine learning models, although some news organisation guidelines on AI specify that the development should involve a diversity of people and cultures — few make reference to the need for the same consideration with regard to models’ training material. Exceptions include the Guardian’s reference to “the dangers of bias embedded within generative tools and their underlying training sets”, the Dutch news agency Algemeen Nederlands Persbureau (ANP), which “does no more than name the risk and take it into account when assessing tools”, the News Media Alliance, which seeks to “avoid discriminatory outcomes” and Bayerischer Rundfunk (BR), which:
“[Discusses] the “integrity and quality of the training data” as a matter of principle, even for internal developments. According to them, minimizing algorithmic distortion helps to “reflect the diversity of society” that the broadcaster highlights in its guidelines … BR is the only organization to go further than addressing only the quality of the training data, also looking at the quality of the other data with which the model works. The Munich-based organization undertakes to maintain employees’ “awareness of the value of data and consistent data maintenance””
A further issue related to diversity is raised by AI’s potential to produce personalised content. The danger of audiences being exposed to less diverse material has led to guidelines that such content “may clash with the mission of offering a diversity of information to the public”, with the advice that it “should respect information integrity and promote a shared understanding of relevant facts and viewpoints”.
Conclusions
What is striking from this exploration of AI in investigative journalism is both the range of technologies, and the ways in which those have been used. And this does not include the range of ways in which investigative journalists are using generative AI tools in particular for more routine tasks, such as idea generation and research, planning, editorial feedback (e.g. identifying jargon and potential bias in story drafts), publication and distribution.
Already a ‘second generation’ of generative AI tools and ‘custom GPTs’ based on ChatGPT has emerged for journalistic use. Examples include the document analysis tool EmbedAI; AI OSINT (investigating domains and emails); Fintool (company data); and AI Search Whisperer (for forming advanced search queries). Journalists who use programming languages in their investigations are also likely to accelerate their work through use of generative AI tools that make coding easier.
While there are a number of challenges for news organisations using AI in investigations, from accuracy and fairness to resources and explainability, one area which requires further research is the more subtle impact on the working process — and the new work created alongside the efficiencies: the work of finding specific AI tools and learning how to use them; breaking down tasks into AI-amenable steps, or preparing material for AI tools; effective prompt-writing; and editing and checking the results. Monitoring developments and changes in models is likely to become more important, as “the behavior of the “same” LLM service can change substantially in a relatively short amount of time”.
“AI can shape relationships between people as well,” notes one report into the technology, describing one respondent as saying: “instead of asking a colleague for help with a heading, I always ask ChatGPT first.”
This wide range of applications and contexts suggests that the idea of ‘artificial intelligence assisted journalism’ will eventually come to be considered too vague a term to be useful — just as ‘computer assisted reporting’ came to be seen as dated and redundant earlier this century. As literacy in the field increases, research and industry discussion may need to revolve around more specific fields and terms: “machine learning-based journalism”, for example, or “investigating with NLP” — or “custom GPTs in visual investigations”. We should expect a deeper and more critical understanding of artificial intelligence in general as the power of AI is better scrutinised in all aspects of our lives — a process in which journalists will perform a central role.

Pingback: Técnicas más precisas de prompting para potenciar el uso de la IA | ADEPA