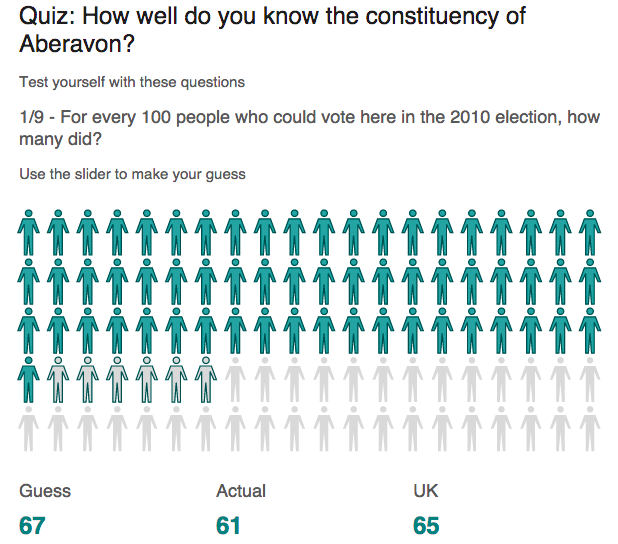
Every so often a journalism student sends me questions for an assignment. I publish the answers here in the FAQ series. The latest set comes from a student in Australia writing for Upstart magazine at La Trobe University, and focuses on the local press.
1. Is the reader not worth as much on the internet?
Readers have always been worth different amounts in different contexts. It’s not that the reader is ‘not worth as much on the internet’, but that most readers on most websites are worth less. Continue reading