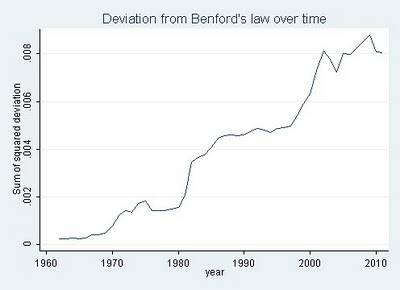
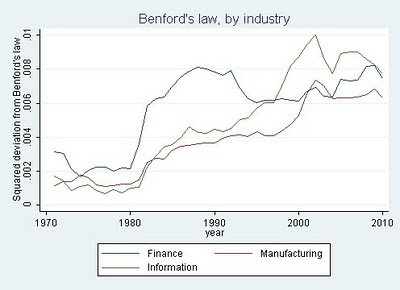
In a move that seemed to upset collectors of UK ministerial meeting data, @whoslobbying, on grounds of wasted effort, the Guardian datastore published a spreadsheet last night containing data relating to ministerial meetings between May 2010 and March 2011.
(The first release of the spreadsheet actually omitted the column containing who the meeting was with, but that seems to be fixed now… There are, however, still plenty of character encoding issues (apostrophes, accented characters, some sort of em-dash, etc) that might cripple some plug and play tools.)
Looking over the data, we can use it as the basis for a network diagram with actors (Ministers and lobbiests) with edges representing meetings between Minsiters and lobbiests. There is one slight complication in that where there is a meeting between a Minister and several lobbiests, we ideally need to separate out the separate lobbiests into their own nodes.

This probably provides an ideal opportunity to have a play with the Stanford Data Wrangler and try forcing these separate lobbiests onto separate rows, but I didn’t allow myself much time for the tinkering (and the requisite learning!), so I resorted to Python script to read in the data file and split out the different lobbiests. (I also did an iterative step, cleaning the downloaded CSV file in a text editor by replacing nasty characters that caused the script to choke.) You can find the script here (note that it makes use of the networkx network analysis library, which you’ll need to install if you want to run the script.)
The script generates a directed graph with links from Ministers to lobbiests and dumps it to a GraphML file (available here) that can be loaded directly into Gephi. Here’s a view – using Gephi – of the hearth of the network. If we filter the graph to show nodes that met with at least five different Ministers…

we can get a view into the heart of the UK lobbying netwrok:

I sized the lobbiest nodes according to eigenvector centrality, which gives an indication of well connected they are in the network.
One of the nice things about Gephi is that it allows for interactive exploration of a graph, For example, I can hover over a lobbiest node – Barclays in this case – to see which Ministers were met:

Alternatively, we can see who of the well connected met with the Minister for Welfare Reform:

Looking over the data, we also see how some Ministers are inconsistently referenced within the original dataset:

Note that the layout algorithm is such that the different representations of the same name are likely to meet similar lobbiests, which will end up placing the node in a similar location under the force directed layout I used. Which is to say – we may be able to use visual tools to help us identify fractured representations of the same individual. (Note that multiple meetings between the same parties can be visualised using the thickness of the edges, which are weighted according to the number of times the edge is described in the GraphML file…)
Unifying the different representations of the same indivudal is something that Google Refine could help us tidy up with its various clustering tools, although it would be nice if the Datastore folk addressed this at source (or at least, as part of an ongoing data quality enhancement process…;-)
I guess we could also trying reconciling company names against universal company identifiers, for example by using Google Refine’s reconciliation service and the Open Corporates database? Hmmm, which makes me wonder: do MySociety, or Public Whip, offer an MP or Ministerial position reconciliation service that works with Google Refine?
A couple of things I haven’t done: represented the department (which could be done via a node attribute, maybe, at least for the Ministers); represented actual meetings, and what I guess we might term co-lobbying behaviour, where several organisations are in the same meeting.







![]()