

In August 2015 Twitter shut down a number of ‘deleted tweets’ archives. Image: TechCrunch
If you rely on Twitter or other social media services to act as a record of history, a series of incidents over the past six months should make you think again – and take control.
It begins in August 2015 when Twitter shut down a network of 30 Politwoops and Diplotwoops sites dedicated to archiving politicians’ tweets around the world. By December the social media service had reversed its decision: but the damage was done.
https://twitter.com/Jim_Edwards/status/679274721574277120
A week before Twitter’s reversal a case involving Bank of America Merrill Lynch highlighted a similar problem.
Business Insider’s Jim Edwards wrote that he had received communication from the bank saying that two of his tweets had been deleted by Twitter after the bank complained about “copyright violation”:
“Needless to say, I deny the allegation. Quoting from or posting a brief segment of a BAML document is not a violation of copyright.”
What did the tweets say? Edwards cannot confidently know, because “now they are deleted, I cannot read them.”
“And this is the most sinister thing about it: I have no idea what Twitter agreed to censor for BAML, and no way of guessing what BAML’s objection was really about.”
Minister ordered to delete tweet
The third example came last month, when the UK health secretary Jeremy Hunt was ordered by a judge to delete a tweet posted during trial proceedings because it could be in contempt of court:
“Jurors are routinely asked when they are sworn in and at the end of each day not to read media reports or conduct their own research into a case. But on 14 January Coulson directed that Hunt’s tweet be taken down and imposed a temporary ban on reporting its existence.”
UPDATE [Jan 17 2016]: Here’s another example following a prominent CEO’s meeting with a politician:
https://twitter.com/Jon_Christian/status/820731151899828225
If you wanted to find out more as a reporter, where would you track down those tweets?
How to create a personal archive of tweets
This is how you can set up your own system for archiving tweets from a public official or organisation, or indeed your own tweets, so that you can trawl back through those archives if you encounter a situation like those detailed above.
First, you will need to create an account at IFTTT.
IFTTT is a site which automates links between different services: in this case you’re going to automate a link between Twitter and a Google spreadsheet (which will act as your archive).
When you first use the site, it will take you through creating an example ‘recipe’ linking two services. You can choose to go through that, or skip it. But you’ll need to do either before the next step.
Click on your name in the upper right corner and select ‘Create‘ to create a new recipe.
You’ll be presented with the phrase ‘ifthisthenthat‘ with the word ‘this’ underlined. Click on ‘this’.

Click on this to set up a Twitter trigger
‘This’ is your trigger channel. Start typing ‘Twitter’ to find that trigger.

The Twitter ‘channel’ allows you to automate processes involving Twitter
Click on the Twitter icon. The first time you do this you will be asked to ‘connect’ IFTTT to Twitter (this authenticates IFTTT to use Twitter to search tweets).
You will then be asked to specify how you will use Twitter as a trigger. The options are shown below.
If you want to archive your own tweets choose ‘New tweet by you’; if you want to archive tweets by a public official or organisation choose ‘New tweet by a specific user’.

The Twitter trigger has various options
If you choose ‘New tweet by a specific user’ you’ll then be prompted to specify which one. You don’t need to include the @ symbol.
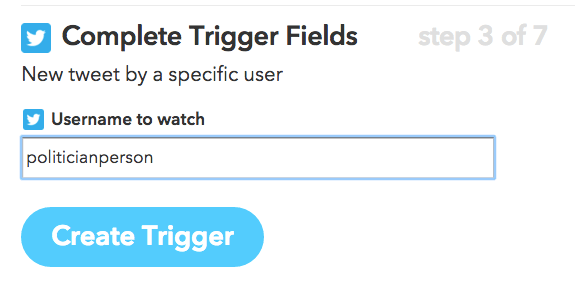
That’s the ‘trigger’ in your recipe created. Now you need to specify what it does when that person tweets: click on the now highlighted ‘that‘ in ‘ifthisthenthat’.
The ‘action’ channel here is going to be Google Drive. Start typing ‘google’ or ‘drive’ in the box to bring it up, then click on the Google Drive icon.
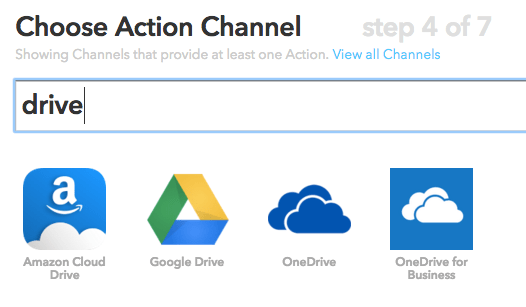
IFTTT also allows you to automatically send files to cloud services
Now you need to specify what it’s going to do in Google Drive when your trigger (a specific user tweeting) is activated. You need to choose ‘Add row to spreadsheet‘.
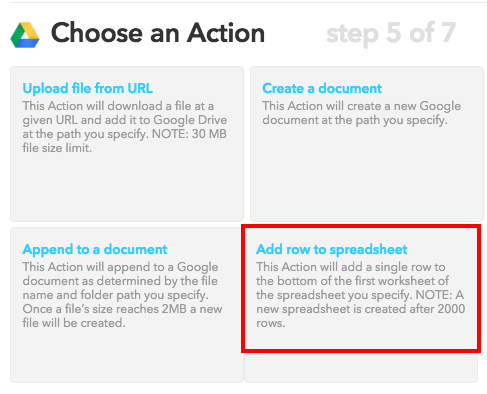
The next step (step 6) will give you some further customisation options. Here you can specify:
- The spreadsheet name (if one doesn’t exist with that name it will create a new one)
- The ‘formatted row’ (what columns the spreadsheet will have, each one separated by |||. Just leave this as is.
- The ‘drive folder path’: where that spreadsheet is going to be placed in your Google Drive. By default it will create a new folder called ‘IFTTT’, and within that another called ‘Twitter’, which is fine.
Click ‘Create Action‘ if you’re happy with those.
You’ve now set up all the steps for your archiving recipe. The final step simply shows you the completed recipe in case you want to change anything. Assuming you don’t, click ‘Create Recipe‘ to complete the process.
That’s it. You’ll now be shown the recipe page. On the right here you can check the ‘log’ of the recipe (how many times it has run and what the results were), run it now (‘check now’), and turn the recipe off if you no longer want to use it.
You can also scroll down to change any of the options in the recipe, such as the username or spreadsheet settings.
Until this recipe runs the first time, there will be no spreadsheet in your Google Drive, so give it at least an hour or so and wait until the account has tweeted, then check your Google Drive for the spreadsheet in question. This will continue to update as new tweets are published.
Note that the recipe only works on tweets published after it has been created; it does not grab older tweets.
Not just Twitter
You can use the same technique for other social media platforms as well: IFTTT has channels for Instagram, Facebook, Tumblr, WordPress and Blogger too.
Limitations
Note that these archives only store the text of the tweet, and not any linked or embedded media.
Other recipes, however, can be used to store a copy of media (posted by Twitter or other accounts) in Google Drive or services such as Dropbox and Evernote.
Ethical issues
Twitter’s decision to block public archiving services was not a black and white one. There is an ethical argument that a private individual has the right to delete their own tweets: not just their ‘right to be forgotten’ but also because the tweet might contain inaccurate information, break laws or be injurious to a third party.
Those arguments need to weighed up against any ethical argument most likely based on a public interest.
But with these techniques you can at least make those decisions yourself, and not trust a commercial organisation to make them for you.

This is really helpful, Paul, thank you for publishing.
Is it possible to automate the downloading of past Facebook posts? Say in a date range. I’ve been collecting some manually but it’s a laborious task. I’ve managed to download to a spreadsheet using a paid service for Twitter but haven’t found anything similar for Facebook.
Not easily afaik know, although I think you can export/request your entire Facebook history?
Yep: https://m.facebook.com/help/212802592074644
Thanks Paul – that’s really helpful. I’m also trying to work out how to download the posts of another account – eg a political party. The only way of managed to do it is to screen grab them. A bit laborious to then get them into a spreadsheet for easy data analysis. I guess Facebook make this deliberately difficult!
You can do this using the Facebook Graph API. It returns results in JSON (which you can then convert using Open Refine into .csv). It’s fiddly but kind of does what you want. To ‘automate’ it I presume someone with more skill than me could write a scraper that did just that.
I have used it to research posts to a local community news page in 2014. I have dumped my rough notes on the process here: https://docs.google.com/document/d/1Z5c4LfCffiZYhB7WdUoRY6lYVi8oVVeU5fTOCQJzDPA/edit?usp=sharing
Great – thanks Dave, I’ll give it a try
Pingback: Journalists need their own archives. Here’s how to start one | Online Journalism Blog