

Tara Calishain used JavaScript to create a collection of tools that save time for journalists conducting research. In a special guest post for OJB, she explains how five of those work.
It’s been over 25 years since I wrote the Official Netscape Guide to Internet Research (and 24 years since I started my blog ResearchBuzz), but search engines and the problem of finding things on the Internet remain just as fascinating to me. Over this summer I began trying to actually solve search challenges instead of just thinking about them — and working out techniques to minimize them.
What changed? I began learning JavaScript! I spent some time in a SkillShare class in May, started a GitHub account in June, and by Labor Day I had a collection of about twenty of what I’m calling ResearchBuzz Search Gizmos.
They’re all freely available at researchbuzz.github.io. Some of them require API keys, but the keys are free as well.
I love all my little Gizmos and could never pick an absolute favorite, but I think these would be most useful to journalists.
Targeted background research: Gossip Machine
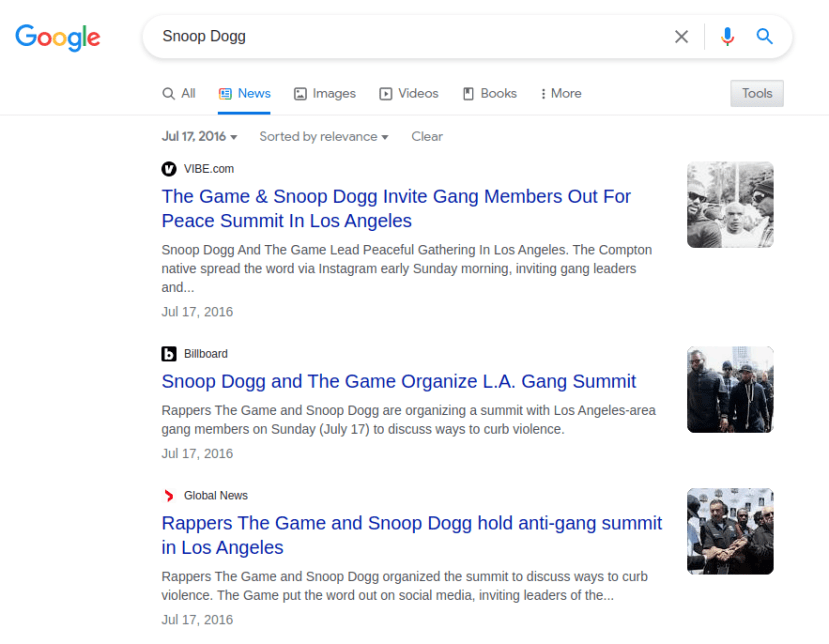
Gossip Machine uses over five years’ worth of page views to surface potential “news days” for any topic with a Wikipedia page (2016-now).
It does this by generating a daily average of page views and then flagging dates which had traffic between 150% and 190% of that average (depending on the setting you use). It then generates pre-filled Google News and Google Web search links for those dates so you can go straight to a (hopefully-useful) Google search for your topic.
A search for ‘Margaret Atwood’ and 2021, for example, throws up four dates. Clicking the Google search link for the first brings up two video clips published on that day from an interview on CBC News.
A search for ‘Olympics’ and 2019 (a year when it wasn’t held), throws up June 24th that year: the associated search link take you to results that tell you why: on that date it was announced that Italy would host the Winter Games in 2026.
It performs best for pages which get more than ~7000 views a day, but even with fewer it works great at digging up news dates.
Search US university pages based on their characteristics: Super Edu Search
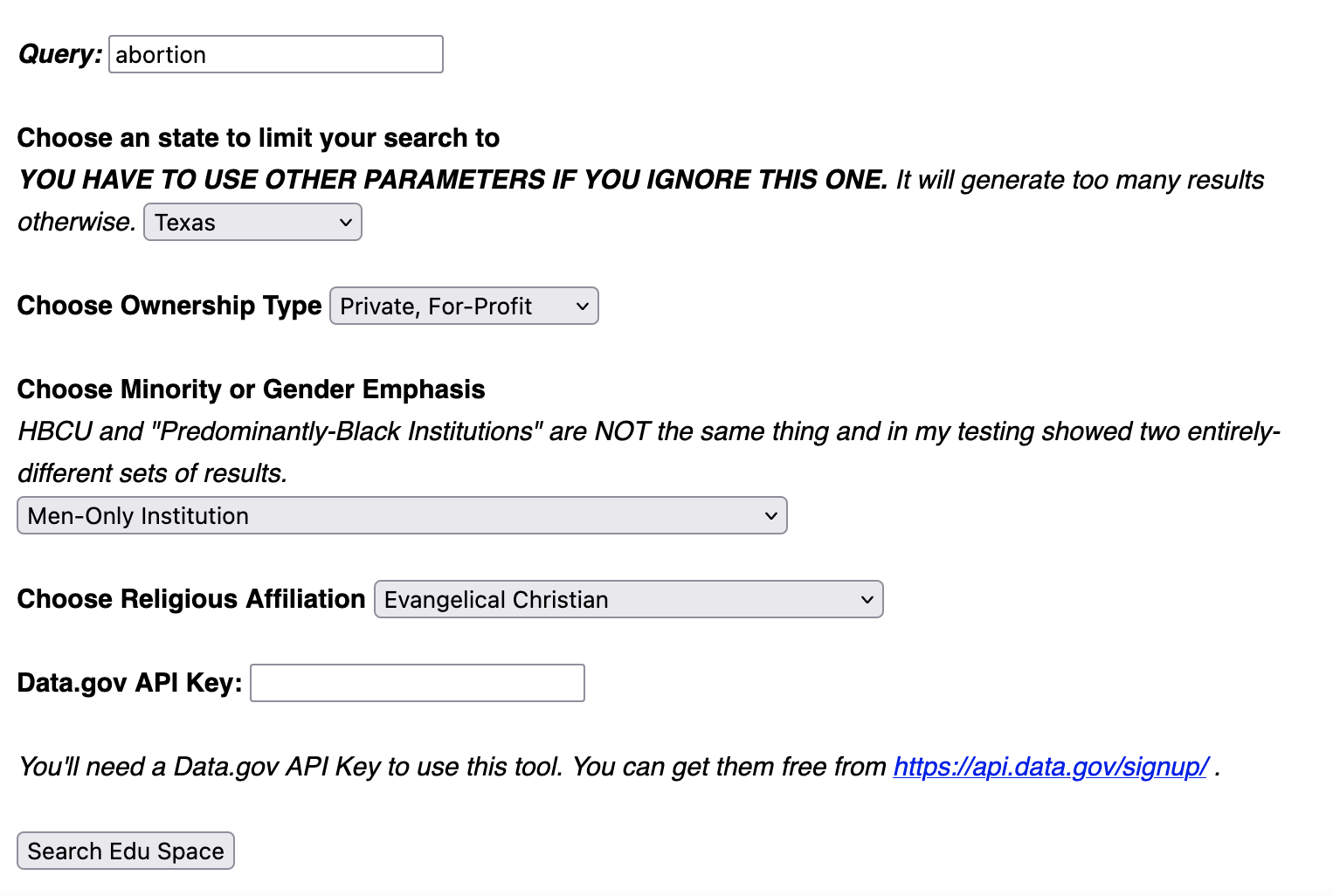
Google’s site:edu search modifier is a great way to instantly make your search results more rich and authoritative, but it’s frustrating to try to filter that space with additional parameters.
Super Edu Search takes higher education institution information from the Department of Education and applies it as a Google search filter. Did you ever want to search the Web space of all the public universities in Indiana? Or all the historically black colleges and universities (HBCUs) in the country? Or maybe all the Baptist institutions in Texas? Now you can. This tool requires a free Data.gov API key.
Create a keyword RSS alert: Kebberfegg RSS Generator
I firmly believe that RSS is the most underrated tech on the Internet. I use RSS feeds daily and I couldn’t produce ResearchBuzz without them. Kebberfegg generates keyword-based RSS feeds (RSS feeds searching a particular resource for a keyword) for about a dozen resources, including Bing, Google News, Reddit, and WordPress.
Save time typing variant searches: Carl’s Name Net
Carl’s Name Net takes a name and optional keywords, generates a set of name variants, and builds those variants into search URLs for Google, Google Books, Google Scholar, and Internet Archive.
For, example, if you typed “John Paul Smith” you’d get search links — for each of those search engines — that combined results for:
- John Smith
- Smith John Paul
- JP Smith, etc.
For the Google searches, it creates two sets of searches: one for common name variants, and one for uncommon. If you don’t specify a middle name, you’ll only get one set of name searches for each resource.
For the Internet Archive, every name gets its own search URL. It’s a fast way to winkle out a bunch of results from unusual places. (For a slightly more extreme way to chase down normally-hidden search results, try The Anti-Bullseye Name Search.)
Search multiple politicians’ output across multiple social platforms: Congressional Social Media Explorer (CSME)
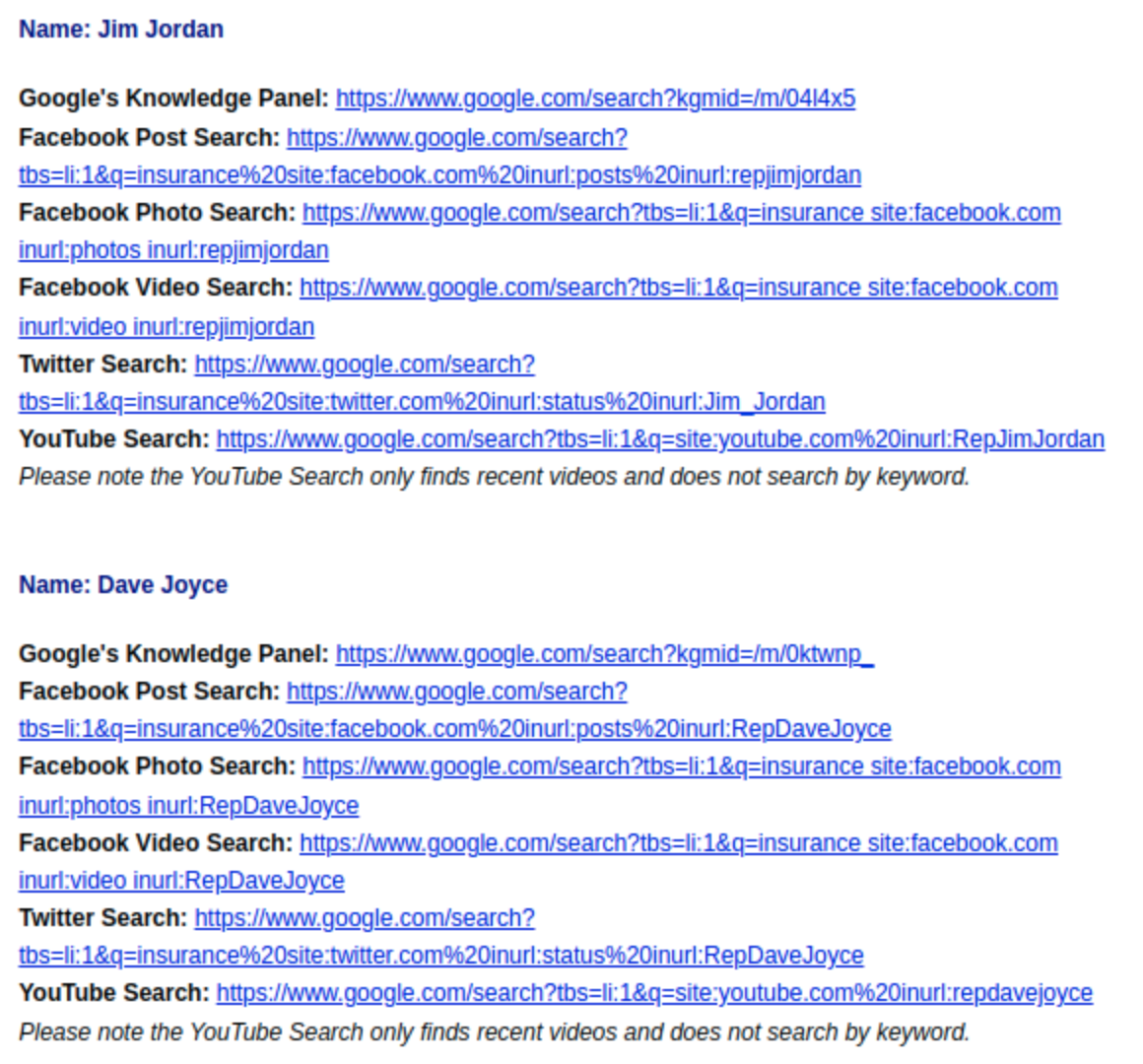
American Congresspeople have a number of social media outlets from which they can speak, but it’s difficult to search across all that space at once. Well, it was, anyway.
CSME takes advantage of a ProPublica API to generate focused Google queries for each member’s social media space.
Specifically it will generate Google queries that will search across a number of members’ Facebook posts, photos and videos, and their Twitter posts.
Queries are generated one state at a time, are available for sessions 112 through 117, and include both the Senate and the House of Representatives.
It’s been a productive summer, but I’ve barely scratched the surface of what I want to make. I feel like I’ve been staring at a nail for 25 years and someone just handed me a hammer. There’s no telling how many Gizmos I’ll have next year at this time!

Pingback: I made a bunch of tools to make journalists’ lives easier. Here are my 5 favourites – Environmental News Bits