This is the fourth in a series of extracts from a draft book chapter on ethics in data journalism. The first looked at how ethics of accuracy play out in data journalism projects, the second at culture clashes, privacy, user data and collaboration, and the third at mass data gathering. This is a work in progress, so if you have examples of ethical dilemmas, best practice, or guidance, I’d be happy to include it with an acknowledgement.
Protection of sources
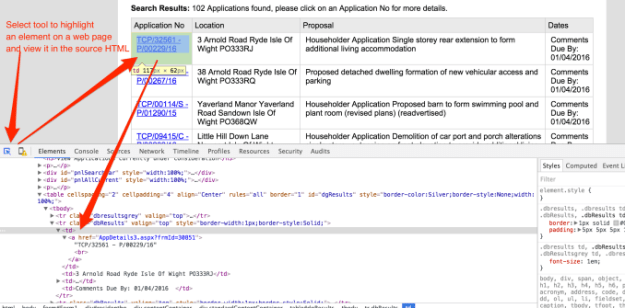
Most news organisations’ professional guidelines include sections on protecting sources. In some countries this is also enshrined in law. Many journalists, however, are not aware of how they can betray sources’ identity by publishing original files online.
Metadata stored in those files – information about the date and location of access, the computers and accounts used, and other data, can be used to identify a leaker. Even photocopied or printed materials can bear invisible digital watermarks which describe what machines were used to produce them, and when (Reimer, 2005; PicMarkr, 2008). Continue reading →





{kind=link}