
UPDATE: A new version of the inverted pyramid, with new stages and resources for each, is now available.
Last week I published an inverted pyramid of data journalism which attempted to map processes from initial compilation of data through cleaning, contextualising, and combining that. The final stage – communication – needed a post of its own, so here it is.
UPDATE: Now in Spanish too.
Below is a diagram illustrating 6 different types of communication in data journalism. (I may have overlooked others, so please let me know if that’s the case.)
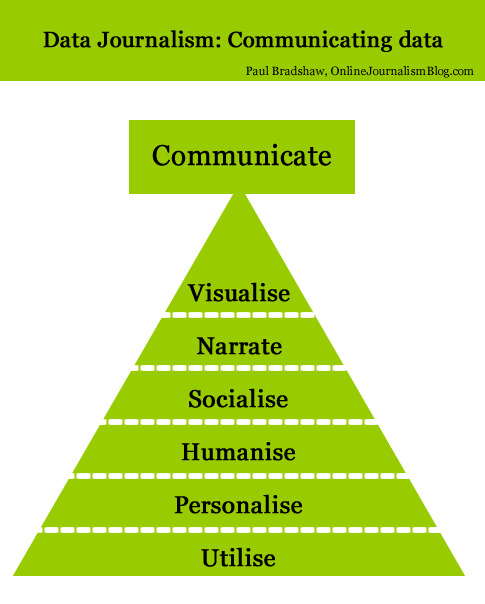
Modern data journalism has grown up alongside an enormous growth in visualisation, and this can sometimes lead us to overlook different ways of telling stories involving big numbers. The intention of the following is to act as a primer for ensuring all options are considered.
1. Visualisation
Visualisation is the quickest way to communicate the results of data journalism: free tools such as Google Docs allow it with a single click; more powerful tools like Many Eyes only require the user to paste their raw data and select from a range of visualisation options.
But ease does not equal effectiveness. The rise of chartjunk illustrates that visualisation is not immune to churnalism or spectacle without insight.
There is a rich history of print visualisation which remains relevant to the generation of online infographics: focusing on no more than 4 data points; avoiding 3D and ensuring the graphic is self-sufficient are just some.
Kaiser Fung’s trifecta is one useful reference point for ensuring a visualisation is effective, and this explanation of how a chart was transformed into something that could be used in a newspaper is also instructive (summarised by Kaiser Fung here).
In short: it’s not a simple process.
Visualisation has one major advantage which makes that effort worthwhile, however: it can make communication incredibly effective. And it can provide a method of distributing your content which cannot be matched by the other types of communication listed here.
But its major strength is also its main weakness, and so it is worth thinking strategically about making sure the image contains a link back to its source.
2. Narration
A traditional article can struggle to contain the sort of numbers that data journalism tends to turf up, but it still provides an accessible way for people to understand the story – if done well.
There are books providing useful guidance on how to write with numbers most clearly – and some guidance for web writing too (you should use numerals rather than words, as this helps people who are scanning the page).
As with visualisation, less is often more. But also, as in most narrative, you need to think about meaningfulness and your objectives in communicating these numbers.
Abstract amounts can be impressive, but meaningless and useless. What does it mean that £10m has been spent on something? Is that more or less than usual? More or less than something similar?
Try to bring down amounts to manageable quantities – the amount per person, or per day, for example.
Finally, use editing to focus in on the essentials: and make sure you link to the whole.
3. Social communication
Communication is a social act, and the success of infographics across social media is a testament to that. But it’s not just infographics that are social – data is too. The Guardian has demonstrated this particularly successfully with the cultivation of a healthy community around its Data Blog (which enjoys higher stickiness than the average Guardian article), and around its API.
Crowdsourcing initiatives aimed at gathering data can also provide a social dimension to the data. The Guardian are, again, pioneers here, with their MPs’ expenses project and Charles Arthur’s attempt to crowdsource predictions about the specifications of the iPad. But there are other examples, too – especially when it is difficult to obtain the data any other way.
The connectivity of the web presents new opportunities to present data journalism in a social way. ProPublica’s app that provides results based on your Facebook profile (schools attended; friends who have used the app) is one example of how data journalism can leverage social data, and, equally, how communicating the results of data journalism can be geared around social dynamics, using elements such as quizzes, sharing, competition, campaigning and collaboration. We are barely at the start of this aspect of online journalism.
4. Humanise
Broadcast news reports often use case studies to get around the problem of presenting numbers-based stories on television and radio. If waiting times have increased, speak to someone who had to wait a long time for an operation. In other words, humanise the numbers.
More recently the growth of computer-generated motion graphics has relaxed that pressure somewhat, as presenters can call on powerful animation to illustrate a story.
But once again, the point of making stories relevant to people comes through. As I wrote in One ambassador’s embarrassment is a tragedy, 15,000 civilian deaths is a statistic: when you move beyond scales we can deal with on a human level, you struggle to engage people in the issue you are covering – no matter how impressive the motion graphics (that post outlines some other considerations in humanising stories, such as ensuring that case studies are representative).
So after being buried in abstract data we need to remember that going out and recording an interview with a person whose life has been affected by that data can make a big difference to the power of our story.
One of the best examples I’ve seen comes from one of my students, Sam Creighton, whose post takes census data as the launchpad for an exploration of the Yiddish-speaking community in Hackney.
5. Personalise
One of the biggest changes in journalism’s move online is that it opens up all sorts of possibilities around interactivity. When it comes to data journalism that means that the user can, potentially, control what information is presented to them based on various inputs.
There are some relatively well-established forms of this. For example, when a government presents its latest budget, news websites often invite the user to input their own details (for example, their earnings, or their family make up) to find out how the budget affects them. A recent variant of this are those interactives which invite the user to make their own decisions on how they might cut the deficit (the FT’s version took this further, adding in party strategies and policies).
Another common form is geographical personalisation: the user is invited to enter their postcode, zip code or other geographical information to find out how a particular issue is playing out in their home town.
A third is simply ‘your interests’, as demonstrated by Popvox’s approach to political engagement and the LA Times’ Newsmatch.
As more and more personal data is held by third party sites, the possibilities for personalisation expand. The ProPublica example given above, for example, demonstrates how Facebook profile information can be used to automatically personalise the experience of a story. And there are various apps that offer to present information based on location data provided via GPS.
This also indicates that there may be various ways in which personalisation and social strategies might be combined. Personalised stories can, in many ways, be used as an expression of our identity: this is where I live; this is how I am affected; this is what I’m interested in.
And when the COO of Facebook is predicting that all media will be personalised in 3-5 years, it’s clear that this is something the social networks are going to drive towards too.
6. Utilise
The most complex way of communicating the results of data journalism is to create some sort of tool based on the data. Calculators are popular choices, as are GPS-driven tools, but there is a lot of scope for more complex applications as more data becomes available both from the publisher and the user [UPDATE: Browser extensions, such as The Markup’s Amazon Brand Detector (based on an investigation) or the Washington Post’s Trump factchecker extension, are another example].
Again, there is overlap here with personalisation – but it is possible to provide utility without personalisation. And quite often, the complexity and consequent barrier to competitors presents commercial opportunities too.
At Reed Business Information, for example, their model is geared towards this sort of utility: attracting users at various points of the communication chain – online updates, printed magazines, mobile news – and steering them towards the point where they are closest to a purchasing decision. The idea is that the closer your information is to their action, the more valuable it is to the user.
At the BBC specials editor Bella Hurrell recommends picking “subjects that have a shelf life”:
“road traffic accidents, unemployment, that sort of thing, Update the data and people will keep coming back. Make tools they will want to keep using. Build sharing into it.”
Running other forms of storytelling alongside it – visualisation of the most interesting viewpoints; liveblogging one day’s data – helps.
Creating utility from data is currently relatively costly – but those costs are going down as a result of competition and standardisation. For example, as increasing numbers of news organisations adopt standard ways of storing story data (e.g. XML files), it is easier to create apps that pull data from datasets. Meanwhile, app creation becomes increasingly templated (in many ways you can see the process following a similar path to that of web design) and platform independent.
A medium up for grabs
What all of the above makes apparent – and I may have missed other methods of communicating data journalism (please let me know if you can think of any [UPDATE: sonification and data art now added]) – is that there are whole areas of online journalism that have yet to be properly explored, and certainly most have yet to establish clear conventions or ideas of best practice.
I’ve tried to scope out an overview of those conventions that are emerging, and the best practice that’s currently available, but it would be great if you could add more. What makes for good humanisation? Utility? What are great examples of personalisation or data journalism that involves a social dimension? Comments below please.
Meanwhile, here are both parts of the model shown together (click to magnify):

UPDATE (22 June 2012): Andy Kirk has tackled a similar process from the designer/developer point of view and comes up with a very useful ‘8 hats of data visualisation’ concept (embedded below). These are:
- Initiator (comes up with a problem or question)
- Data scientist (compiles the data)
- Journalist (narrates)
- Computer scientist (designs a user experience – akin to the ‘utility’ element of communication above)
- Designer (designs user experience and/or visual communication)
- Cognitive scientist (ensures visual communication is effective)
- Communicator (deals with the client)
- Project manager
For the last ‘hat’, slides 57-62 are particularly useful in outlining a critical path for managing a visualisation project.
UPDATE (August 2020): A Ukrainian version of the inverted pyramid has now been made:
UPDATE (October 2020): The inverted pyramid was used as a framework for research on “Data Journalism in the Spanish Caribbean Digital Media”
UPDATE (December 2021): A Russian version of the inverted pyramid has now been made:
UPDATE (July 2023): A German version of the pyramid is available.

UPDATE [July 2025]: I’ve added sonify/materialise to the stages: sonification of data (turning into sound) and turning data into physical objects (e.g. art exhibits).

Pingback: META: Journalism worldwide. « wikinews030.
Pingback: In Spanish: The inverted pyramid of data journalism part 2 | Online Journalism Blog
This is an interesting concept. Just another example of all the different ways to communicate a message to the public. Thanks for sharing!
Pingback: Data journalism: raccogliere, verificare e comunicare le informazioni in rete | Senzamegafono
Pingback: LSDI : Data journalism/2: le due piramidi di Paul Bradshaw
Pingback: Daniela Osvald Ramos » Blog Archive » Visualização de dados
Pingback: Hur man skapar ordmoln // Anna Norberg
Pingback: Step by step: how to start in a data journalist role | Online Journalism Blog
Pingback: TKTK « Fenton | Progress Accelerated
Pingback: itsdevelopmental.com ~ Thoughts on feature writing
I must admit I haven’t seen this pyramid it is quite interesting.
Journalism is one of the most important way to share information and events that are happening in our world, so their communication skills must be perfect.
Pingback: The inverted pyramid of data journalism – DATOVÁ ŽURNALISTIKA
I would change the order in “8 hats of data visualization”, so that 5 and 6 come before 4. Designer is not for making a gloss there, but to design the graphical logic, that computer scinetist then will try to implement.
Good point.
Pingback: The inverted pyramid of data journalism | DATOVÁ ŽURNALISTIKA
Pingback: 6 manieren om datajournalistiek te communiceren of de opgekeerde pyramide van datajournalistiek deel 2 - Datajournalistiek.nl
Pingback: Garbage in, News Out. | AIR
Pingback: No, Data Journalism is not the future journalism! | artsmakedifference
Pingback: Secrets of Success for a Media Professional – a whole lot of writing
Pingback: 6 ways of communicating data journalism (The inverted pyramid of data journalism part 2) | Online Journalism Blog
Pingback: Here’s the thinking behind my new MA in Data Journalism | Online Journalism Blog
Pingback: Here’s the thinking behind my new MA in Data Journalism – Digital Future
Pingback: Jornalismo de dados: apuração, análise e formas de visualização | Lise Brenol
Pingback: The inverted pyramid of data journalism | Online Journalism Blog