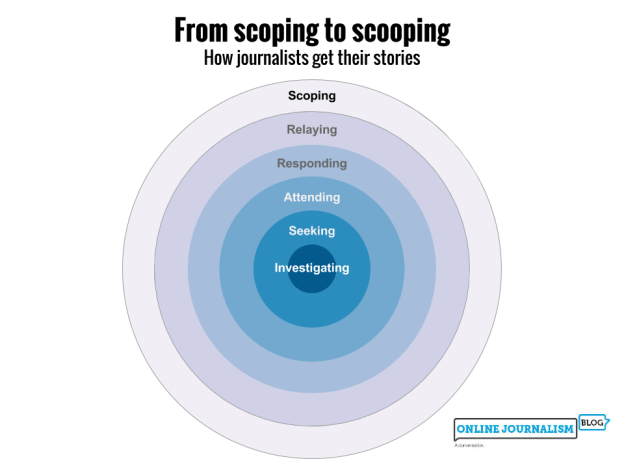
When you’re dealing with documents amounting to 2.6million words spread across over 50 PDFs, you need to do more than just be able to press the CTRL and F keys together.
And yet political journalists across the country will be relying on just that to report on the Chilcot Report into the UK’s involvement in the Iraq war (also known as the Iraq Inquiry) this week.
I’ve uploaded all the PDFs to the document analysis service DocumentCloud. You can find them on the site here. You’ll need a DocumentCloud account to see it, but if you haven’t got an account you can also search all 55 documents at the same time in an embedded search I’ve created over on HelpMeInvestigate.
Entities
One of the advantages of using a service like DocumentCloud is ‘entity analysis’. This basically goes through the documents and identifies entities such as people, places, organisations and ‘terms’ (for example: ‘chemical warfare’), treating each type of entity separately and creating a little histogram showing where those entities are mentioned in the document.
To view the documents in this way, you just need to click the ‘Analyze’ button in DocumentCloud and choose the view you want:

Click the Analyze button to see the documents by timeline or entities
‘View Entities’ gives you a view like the one shown below:

In the entity analysis view you can see that the Ministry of Health is mentioned a lot towards the end of this document
If you hover over any of those little bars you should see a popup showing the context within which the entity is mentioned…

Hovering over this bar shows the text surrounding the location identified
And you can click to see the raw text in full:

If you choose the Analyze Timeline option DocumentCloud will show you a timeline of events it has identified in the selected documents. This allows you to spot outliers (such as the earliest events in the narrative), clusters, or to zoom into a particular key period.

You can click and drag to zoom in. Again by hovering over any point you will see a preview of the context within which a date is mentioned, and can click on that to see the original text in full.

Those are just some of the basic ways in which DocumentCloud makes interrogating documents much quicker. You can also use Overview to analyse it in other ways, but that’s another story…

How the Chilcot report looks in Overview