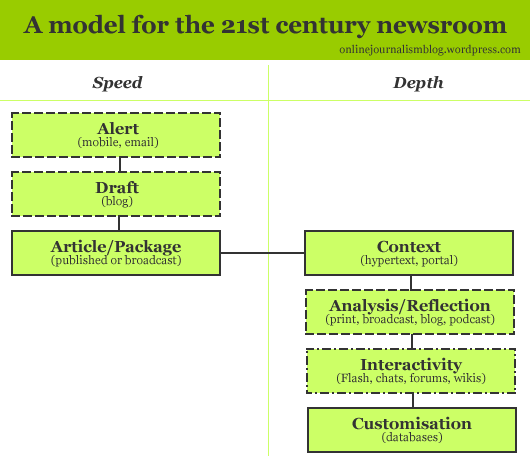
Here’s a wonderful reimagining of the News Diamond from the first part of my Model for a 21st Century Newsroom. Gaurav Mishra’s diagram (shown above) takes my rhombus (shown below) and plots it against two axes. It’s rather lovely.
Helpfully, however, Mishra takes the concept forward a little. As he explains:
“my “news lifecycle” is different from Paul Bradshaw’s “news diamond” in two ways –
“1. Paul’s “news diamond” looks at news from a news organization’s perspective, whereas my “news lifecycle” acknowledges that the boundaries between news creators, news curators and news consumers have blurred beyond recognition.
“2. Paul does not make the distinction between unplanned breaking news events (like accidents and terrorist attacks) and planned live coverage of events (like the Super Bowl or the US presidential inauguration). Paul’s “news diamond” and my “news lifecycle” models are much more valid for unplanned breaking news events.”
It’s fair to say that my diamond does take the perspective of a news organisation – that’s who it was aimed at. But I’m not sure that that means it doesn’t acknowledge the blurring of boundaries.
Anyway, Mishra poses some questions:
- How do we increase the number and variety of sources in the process of creating, curating and consuming news?
- How do we separate signal from noise during each stage of the news lifecycle?
- How do we contract the “alert” to “analysis” stages of the news lifecycle, in order to get better signal to noise ratio sooner in the cycle?
- How to we expand the “conversation” to “customization” stages of the news lifecycle, in order to maximize the returns from the content we have created?
- How do we expand the requisite participatory media ecosystem so that exceptions to this news lifecycle (like the information void in the Israel-Hamas Gaza conflict or the Russia-Georgia Otessia conflict) become increasingly rare?
I’d be very interested in any responses.
In the meantime, here’s those original diagrams for your conceptual enjoyment…

As it happens, the diamond was just another way of showing the following flow diagram from the same post, so now I have 3 diagrams to refer to…