
The story found that most requests were made by private individuals, not politicians or criminals. Image: The Guardian
Sylvia Tippmann wasn’t looking for a story. In fact, she was working on a way that Google could improve the way that it handled ‘right to be forgotten‘ processes, when she stumbled across some information that she suspected the search giant hadn’t intended to make public.
Two weeks ago The Guardian in the UK and Correct!v in Germany published the story of the leaked data, which was then widely picked up by the business and technology press: Google had accidentally revealed details on hundreds of thousands of ‘right to be forgotten’ requests, providing a rare insight into the controversial law and raising concerns over the corporation’s role in judging requests.
But it was the way that Tippmann stumbled across the story that fascinated me: a combination of tech savvy, a desire to speed up work processes, and a strong nose for news that often characterise data journalists’ reporting. So I wanted to tell it here.
“Because I am lazy”
Tippmann was working on “a serious solution for [the right to be forgotten] problem” to pitch to Google when she noticed in the company’s transparency report that the compliance rate between countries varied noticeably.
“Because I am lazy, I just wanted to scrape the data to make a more comparative chart, when – after a bit of time and a face-palm – I realised that it was plainly in the source code.”
Why the face-palm? Normally that information would be stored in a separate data file, typically in the JSON format.
“To identify those data files open Web Developer in the browser’s Tools menu (I use Firefox), go on the ‘network monitor’ tab, reload the page and look for any .js, .json (or .csv, .tsv) files in the list. When you click on each loaded file, the ‘Request URL’ reveals the location of the data, which is what can be scraped.
“This is what I looked for first, unsuccessfully, on the Transparency Report”
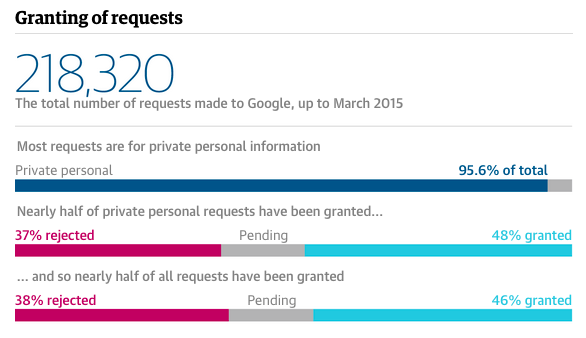
But it wasn’t just the report data that was in the source code: the code also revealed the more detailed numbers behind the totals, including classification of requests as ‘political’, ‘public figure’, ‘serious crime’, ‘private personal info’ or ‘cp’ (child protection), and whether requests had been rejected, complied with, were still pending, or needed more information,

A sample of the source code that revealed more granular detail about the right to be forgotten requests
“When I found that all this additional data was there I got some friends to take snapshots of the website’s HTML independently.
“That’s not the way to structure a website, by the way”
“I could only publish this with numerate journalists”
The page has since been changed but the Internet Archive still maintains cached versions here.
“I spent a weekend analysing everything, because there was a lot of inconsistency, and compiled a package with a pitch, R scripts, graphics, an interactive and a solid documentation.
“I decided that I could only publish this with an outlet that has some numerate journalists to peer-review and to support and advise me legally.
Journalists at the Guardian initially didn’t warm to the story, and it was difficult for Tippmann to send specific details because they didn’t use PGP (encrypted email). But Correct!v were “more fit technically” and agreed to do the story.
It was only when interviewing a Guardian contributor for the story that she found a natural fit in the newspaper: lawyer and Cambridge academic Julia Powles.
“She was so excited about it that she made the case for it to the Guardian. They came on board under the condition to that someone there would independently validate my analysis.”
Sylvia was confident (she does after all have a background, in computational genetics and over 4 years experience as a doctoral researcher in bioinformatics) but was keen to have the work peer-reviewed, and – four months after coming across the data – the story was published.
“At the moment they are plain text files without meta tags”
Or at least, the start of it was. The articles focused on key countries and specific details, so Sylvia set up a website to present the full background. And she still feels that there is a lot more to be done with the data.
“There are still a couple of things that don’t add up and a highly varying application rate per country, which I would like to follow up.
“I would like to create a website which not only explores data but also features separate investigations in each country and has multi-language functionality to allow journalists to get the data and contribute to it.
“I want to make the Advisory Council hearings more searchable – at the moment they are plain text files without meta tags – and help expose the interesting bits in it. And hopefully bring in some of Julia Powles’ research and contributions from other experts.”
The problem, of course, is money.
In the meantime, you can read more about Sylvia’s methods here, and the coverage here, and contact Sylvia here. Of course, it helps if you can use PGP…

Reblogged this on U Learn Journ(alism) and commented:
Kind of tech jargony but interesting
Reblogged this on Onlyjustwords and commented:
We can get as specific as we need to get to make our point.
“reload the page and look for any .js, .json (or .csv, .tsv) files in the list. When you click on each loaded file, the ‘Request URL’ reveals the location of the data,”
a little tip to add to this technique….if you find a .json file (which is commonly where most of the data is stored), you can turn that into an Excel spreadsheet (CSV) by pasting the URL or JSON data into:
https://json-csv.com