Some posts I get a little bit twitchy about writing. Accessing and Visualising Sentencing Data for Local Courts was one, and this is another: exploring practice level prescription data (get the data).
One of the reasons it feels “dangerous” is that the rationale behind the post is to demonstrate some of the mechanics of engaging with the data at a context free level, devoid of any real consideration about what the data represents, whilst using a data set that does have meaning, the interpretation of which can be used as the basis of making judgements about various geographical areas, for example.
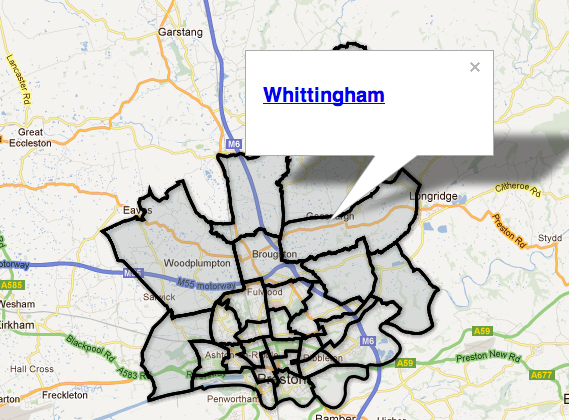
The datasets that are the focus of this post relate to GP practice level prescription data. One datafile lists GP practices (I’ve uploaded this to Google Fusion tables), and includes practice name, identifier, and address. I geocoded the Google Fusion tables version of the data according to practice postcode, so we can see on a map how the practices are distributed:

(There are a few errors in the geocoding that could probably be fixed by editing the correspond data rows, and adding something like “, UK” to the postcode. (I’ve often thought it would be handy if you could force Google Fusion Table’s geocoder to only return points within a particular territory…))
The prescription data includes data at the level of item counts by drug name or prescription item per month for each practice. Trivially, we might do something like take the count of methadone prescriptions for each practice, and plot a map sizing points at the location of each practice by the number of methadone prescriptions by that practice. All well and good if we bear in mind the fact the the data hasn’t been normalised by the size of the practice, doesn’t take into account the area over which the patients are distributed, doesn’t take into account the demographics of the practices constituency (or recognise that a particular practice may host a special clinic, or the sample month may have included an event that drew in a large transient population with a particular condition, or whatever). A good example to illustrate this taken from another context might be “murder density” in London. It wouldn’t surprise me if somewhere like Russell Square came out as a hot spot – not because there are lots of murders there, but because a bomb went off on a single occasion killing multiple people… Another example of “crime hot spots” might well be courts or police stations, places that end up being used as default/placeholder locations if the actual location of crime isn’t known. And so on.
The analyst responsible for creating quick and dirty sketch maps will hopefully be mindful of the factors that haven’t been addressed in the construction of a sketch, and will consequently treat with suspicion any result unless they’ve satisfied themselves that various factors have been taken into account, or discount particular results that are not the current focus of the question they are asking themselves of the data in a particular way.
So when it comes to producing a post like this looking at demonstrating some practical skills, care needs to be taken not to produce charts or maps that appear to say one thing when indeed they say nothing… So bear that in mind: this post isn’t about how to generate statistically meaningful charts and tables; it’s about mechanics of getting rows of data out of big files and into a form we can start to try to make sense of them
Another reason I’m a little twitchy about this post relates to describing certain skills in an open and searchable/publicly discoverable forum. (This is one reason why folk often demonstrate core skills on “safe” datasets or randomly generated data files.) In the post Googling Nasties and Oopses on University and Public Sector Websites, a commenter asked: “is it really ethical to post that information?” in the context of an example showing how to search for confidential spreadsheet information using a web search engine. I could imagine a similar charge being leveled at a post that describes certain sorts of data wrangling skills. Maybe some areas of knowledge should be limited to the priesthood..?
To mitigate against any risks of revealing things best left undiscovered, I could draw on the NHS Information Centre’s Evaluation and impact assessment – proposal to publish practice-level prescribing data[PDF] as well as the risks acknowledged by the recent National Audit Office report on Implementing transparency (risks to privacy, of fraud, and other possible unintended consequences). But I won’t, for now…. (dangerrrrrroussssssssss…;-)
(Academically speaking, it might be interesting to go through the NHS Info Centre’s risk assessment and see just how far we can go in making those risks real using the released data set as a “white hat data hacker”, for example! I will go through the risk assessment properly in another post.)
So… let the journey into the data begin, and the reason why I felt the need to have a play with this data set:
Note: Due to the large file size (over 500MB) standard spreadsheet applications will not be able to handle the volumes of data contained in the monthly datasets. Data users will need to analyse the information using specialist data-handling software.
Hmmm… that’s not very accessible is it?!
However, if you’ve read my previous posts on Playing With Large (ish) CSV Files or Postcards from a Text Processing Excursion, or maybe even the aforementioned local sentencing data post, you may have some ideas about how to actually work with this file…
So fear not – if you fancy playing along, you should already be set up tooling wise if you’re on a Mac or a Linux computer. (If you’re on a Windows machine, I cant really help – you’ll probably need to install something like gnuwin or Cygwin – if any Windows users could add support in the comments, please do:-)
Download the data (all 500MB+ of it – it’s published unzipped/uncompressed (a zipped version comes in at a bit less than 100MB)) and launch a terminal.
>
I downloaded the December 2011 files as nhsPracticesDec2011.csv and nhsPrescribingDataDec2011.CSV so those are the filenames I’ll be using.
To look at the first few lines of each file we can use the head command:
head nhsPrescribingDataDec2011.CSV
head nhsPracticesDec2011.csv
Inspection of the practices data suggests that counties for each practice are specified, so I can generate a subset of the practices file listing just practices on the ISLE OF WIGHT by issuing a grep (search) command and sending (>) the result to a new file:
grep WIGHT nhsPracticesDec2011.CSV > wightPracDec2011.csv
The file wightPracDec2011.csv should now contain details of practices (one per row) based on the Isle of Wight. We can inspect the first few lines of the file using the head command, or use more to scroll through the data one page at a time (hit space bar to move on a page, ESCape to exit).
head wightPracDec2011.csv
more wightPracDec2011.csv

Hmmm.. there’s a rogue practice in there from the Wirral – let’s refine the grep a little:
grep 'OF WIGHT' nhsPracticesDec2011.CSV > wightPracDec2011.csv
more wightPracDec2011.csv
From looking at the data file itslef, along with the prescribing data release notes/glossary, we can see that each practice has a unique identifier. From previewing the head of the prescription data itself, as well as from the documentation, we know that the large prescription data file contains identifiers for each practice too. So based on the previous steps, can you figure out how to pull out the rows from the prescriptions file that relate to drugs issued by the Ventnor medical centre, which has code J84003? Like this, maybe?
grep J84003 nhsPrescribingDataDec2011.CSV > wightPrescDec2011_J84003.csv
head wightPrescDec2011_J84003.csv
(It may take a minute or two, so be patient…)
We can check how many rows there actually are as follows:
wc -l wightPrescDec2011_J84003.csv
I was thinking it would be nice to be able to get prescription data from all the Isle of Wight practices, so how might we go about that. From reviewing my previous text mining posts, I noticed that I could pull out data from a file by column:
cut -f 2 -d ',' wightPracDec2011.csv
This lists column two of the file wightPracDec2011.csv where columns are comma delimited.
We can send this list of codes to the grep command to pull out records from the large prescriptions file for each of the codes we grabbed using the cut command (I asked on Twitter for how to do this, and got a reply back that seemed to do the trick pretty much by return of tweet from @smelendez):
cut -d ',' -f 2 wightPracDec2011.csv | grep nhsPrescribingDataDec2011.CSV -f - > iwPrescDec2011.csv
more iwPrescDec2011.csv
We can sort the result by column – for example, in alphabetic order by column 5 (-k 5), the drugs column:
sort -t ',' -k 5 iwPrescDec2011.csv | head
Or we can sort by decreasing (-r) total ingredient cost:
sort -t ',' -k 7 -r iwPrescDec2011.csv | head
Or in decreasing order of the largest number of items:
sort -t ',' -k 6 -r iwPrescDec2011.csv | head

One problem with looking at those results is that we can’t obviously recognise the practice. (That might be a good thing, especially if we looked at item counts in increasing order… Whilst we don’t know how many patients were in receipt of one or more items of drug x if 500 or so items were prescribed in the reporting period across several practices, if there is only one item of a particular drug prescribed for one practice, then we’re down to one patient in receipt of that item across the island, which may be enough to identify them…) I leave it as an exercise for the reader to work out how you might reconcile the practice codes with practice names (Merging Datasets with Common Columns in Google Refine might be one way? Merging Two Different Datasets Containing a Common Column With R and R-Studio another..?).
Using the iwPrescDec2011.csv file, we can now search to see how many items of a particular drug are prescribed across island practices using searches of the form:
grep Aspirin iwPrescDec2011.csv
grep 'Peppermint Oil' iwPrescDec2011.csv

And this is where we now start to need taking a little care… Scanning through that data by eye, a bit of quick mental arithmetic (divide column 7 by column 6) suggests that the unit price for peppermint oil is different across practices. So is there a good reason for this? I would guess that the practices may well be describing different volumes of peppermint oil as single prescription items, which makes a quick item cost calculation largely meaningless? I guess we need to check the data glossary/documentation to confirm (or deny) this?
Okay – enough for now… maybe I’ll see how we can do a little more digging around this data in another post…
PS Just been doing a bit of doing around other GP practice level datasets – you can find a range of them on the NHS Indicator Portal. As well as administrative links up to PCT and Stategic Health Authority names, you can get data such as the size and demographic make up of each practice’s registration list, data relating to deprivation measures, models for incidence of various health conditions, practice address and phone number, the number of nursing home patients, the number of GPs per practice, the uptake of various IT initiatives(?!), patient experience data, impact on NHS services data… (Apparently a lot of this ata is available in a ‘user friendly’ format on NHS Choices website, but I couldn’t find it offhand… as part of the GP comparison service. Are there any third party sites around built on top of this data also?)