Image by dullhunk on Flickr
Here’s another Something for the Weekend post. Last week I wrote a post on how to use the =importFeed formula in Google Docs spreadsheets to pull an RSS feed (or part of one) into a spreadsheet, and split it into columns. Another formula which performs a similar function more powerfully is =importXML.
There are at least 2 distinct journalistic uses for =importXML:
- You have found information that is only available in XML format and need to put it into a standard spreadsheet to interrogate it or combine it with other data.
- You want to extract some information from a webpage – perhaps on a regular basis – and put that in a structured format (a spreadsheet) so you can more easily ask questions of it.
The first task is the easiest, so I’ll explain how to do that in this post. I’ll use a separate post to explain the latter.
Converting an XML feed into a table
If you have some information in XML format it helps if you have some understanding of how XML is structured. A backgrounder on how to understand XML is covered in this post explaining XML for journalists.
It also helps if you are using a browser which is good at displaying XML pages: Chrome, for example, not only staggers and indents different pieces of information, but also allows you to expand or collapse parts of that, and colours elements, values and attributes (which we’ll come on to below) differently.
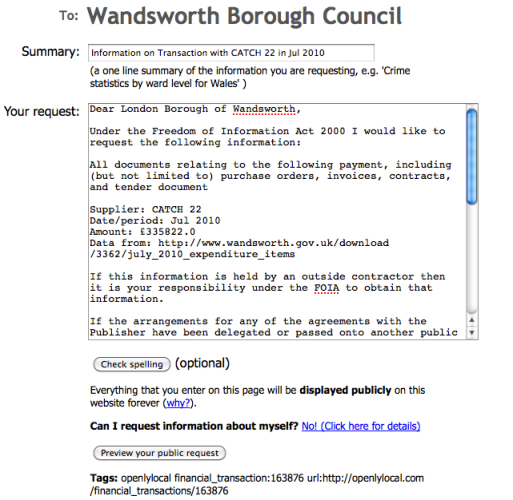
Say, for example, you wanted a spreadsheet of UK council data, including latitude, longitude, CIPFA code, and so on – and you found the data, but it was in XML format at a page like this: http://openlylocal.com/councils/all.xml
To pull that into a neatly structured spreadsheet in Google Docs, type the following into the cell where you want the import to begin (try typing in cell A2, leaving the first row free for you to add column headers):
=ImportXML(“http://openlylocal.com/councils/all.xml”, ”//council”)
The formula (or, more accurately, function) needs two pieces of information, which are contained in the parentheses and separated by a comma: a web address (URL), and a query. Or, put another way:
=importXML(“theURLinQuotationMarks”, “theBitWithinTheURLthatYouWant”)
The URL is relatively easy – it is the address of the XML file you are reading (it should end in .xml). The query needs some further explanation.
The query tells Google Docs which bit of the XML you want to pull out. It uses a language called XPath – but don’t worry, you will only need to note down a few queries for most purposes.
Here’s an example of part of that XML file shown in the Chrome browser:

The indentation and triangles indicate the way the data is structured. So, the <councils> tag contains at least one item called <council> (if you scrolled down, or clicked on the triangle to collapse <council> you would see there are a few hundred).
And each <council> contains an <address>, <authority-type>, and many other pieces of information.
If you wanted to grab every <council> from this XML file, then, you use the query “//council” as shown above. Think of the // as a replacement for the < in a tag – you are saying: ‘grab the contents of every item that begins <council>’.
You’ll notice that in your spreadsheet where you have typed the formula above, it gathers the contents (called a value) of each tag within <council>, each tag’s value going into their own column – giving you dozens of columns.
You can continue this logic to look for tags within tags. For example, if you wanted to grab the <name> value from within each <council> tag, you could use:
=ImportXML(“http://openlylocal.com/councils/all.xml”, ”//council//name”)
You would then only have one column, containing the names of all the councils – if that’s all you wanted. You could of course adapt the formula again in cell B2 to pull another piece of information. However, you may end up with a mismatch of data where that information is missing – so it’s always better to grab all the XML once, then clean it up on a copy.
If the XML is more complex then you can ask more complex questions – which I’ll cover in the second part of this post. You can also put the URL and/or query in other cells to simplify matters, e.g.
=ImportXML(A1, B1)
Where cell A1 contains http://openlylocal.com/councils/all.xml and B1 contains //council (note the lack of quotation marks). You then only need to change the contents of A1 or B1 to change the results, rather than having to edit the formula directly)
If you’ve any other examples, ideas or corrections, let me know. Meanwhile, I’ve published an example spreadsheet demonstrating all the above techniques here.