
Nas minhas aulas e treinamentos de jornalismo de dados, costumo falar sobre os tipos mais comuns de histórias que podem ser encontradas em bancos de dados. Então, selecionei 100 reportagens baseadas em dados, analisei-as e verifiquei com qual frequência cada um desses ângulos é utilizado.
Cheguei à conclusão de que, na verdade, existem sete ângulos principais para reportagens e histórias baseadas em dados. Muitas histórias incorporam outros ângulos como dimensões secundárias da narrativa (uma história de mudança pode passar a falar sobre a escala de algo, por exemplo), mas todas as histórias de jornalismo de dados que examinei levaram um desses ângulos como fio-condutor.
Neste post, examino como os sete ângulos mais comuns podem ajudar você a ter ideias para histórias e reportagens, assim como a variedade de execuções e as principais considerações para se ter em mente.
Ângulo 1: Escala – “Este é o tamanho do problema”
A pandemia trouxe várias histórias de escalas: esta, do New York Times, ressalta a escala das mortes
Talvez o tipo mais comum de história encontrada em dados seja a história de escala: são histórias que identificam um grande problema ou o tamanho de um problema que se tornou atual.
Da maneira mais simples, as histórias de escala fornecem uma atualização sobre os mais recentes números publicados: podem ser os últimos números do desemprego, a quantidade de crimes, poluição do ar, dinheiro gasto em alguma área, nascimentos, mortes ou casamentos.
Durante os primeiros meses da pandemia, por exemplo, tínhamos histórias diárias de escala sobre o número de casos, mortes e testes, entre outras coisas.
Exemplos de histórias de escala incluem “O número de mortes em lares de idosos no Reino Unido por coronavírus pode ser de 6.000, estima estudo”’, mas também histórias como “Esquema de revisão de sentenças indevidamente lenientes é ‘inadequado”, onde o lead se baseia na reação à escala de um problema.
Às vezes, a escala serve como pano de fundo para um evento único, como em “Drone causa interrupção no aeroporto de Gatwick” (quantos incidentes do tipo ocorreram?), ou para uma nova proposta política, como em “Novos motoristas podem ser proibidos de dirigir à noite’’ (quantos novos motoristas têm menos de 19 anos?).
As histórias em escala são um dos gêneros mais fáceis de escrever: em muitos casos, nenhum cálculo é necessário.
Na verdade, o principal trabalho provavelmente será fornecer contexto para essa escala – senão, uma história em escala acaba se tornando uma história de ‘grande número’ (“Muito dinheiro foi gasto em coisas” ou “Algo acontece a muitas pessoas ”). Sem um contexto, o leitor não entenderá se isso é realmente interessante ou apenas normal.
Por isso, é importante contextualizar a escala usando percentagens ou proporções (por exemplo, “um em cinco”) ou comparações e analogias (“O dinheiro gasto no plano equivale ao salário de 500 professores”).
Você também pode trazer mudanças e / ou variações como um ângulo secundário: estabelecendo o contexto histórico para a escala que você acabou de delinear, ou como essa escala varia.
No artigo do New York Times, por exemplo, o “verdadeiro cenário” (escala) do surto de coronavírus é contextualizado por gráficos que mostram como isso mudou desde o início do ano em diferentes partes do país.
Ângulo 2: Mudança e imobilização – as coisas estão subindo, as coisas estão caindo, as coisas não estão acontecendo

Image: Belfast Telegraph
Histórias de mudança são quase tão comuns quanto histórias em escala – e provavelmente mais simples de publicar.
Afinal, a mudança é inerentemente interessante e dá a você o verbo (“sobe”, “despenca”) necessário para um título.
Depois de identificar algum tipo de alteração em seus dados, é provável que você precise de mais relatórios para responder ao “por quê?“. Por que esses números estão aumentando ou diminuindo?
Você também pode adicionar um ângulo secundário à sua história que explora a variação dessa tendência – as áreas onde esses números aumentaram ou diminuíram.
Isso pode ajudar você a direcionar sua reportagem para o “por quê?”, pois é provável que as áreas mais afetadas sejam aquelas que estão mais cientes do problema e capazes de comentá-lo.
Ao relatar mudanças, é importante fazer duas considerações: sazonalidade e margens de erro.
Sazonalidade é o papel que fatores sazonais (normalmente previsíveis e normais e, portanto, não dignos de notícia) podem desempenhar em números, como o fim de um ano financeiro ou período escolar, o lançamento de novos carros ou simplesmente a mudança de temperatura. Comparações ano a ano (agosto deste ano em comparação com agosto passado, por exemplo) ou ajuste sazonal são frequentemente usados para evitar esse efeito.
A margem de erro, entretanto, é o intervalo no qual os reais números se encontram. Como muitos conjuntos de dados são baseados em amostras que são generalizadas para o resto da população analisada, uma margem de erro (ou intervalos de confiança) é usada para indicar o quão precisa essa generalização realmente é. Se alguma alteração estiver dentro dessa margem de erro, não podemos realmente relatar que algo mudou.
Uma variação desse segundo ângulo para histórias baseadas em dados é também a falta de mudança. Esta história sobre insolvências de empresas, por exemplo, procura mudanças onde você esperaria, mas identifica a ausência de qualquer aumento no número de empresas que quebraram durante a pandemia e busca comentários de especialistas para essa descoberta contra-intuitiva.
Ângulo 3: Classificação e outliers – quem é o melhor e quem é o pior? O que é incomum e por quê?
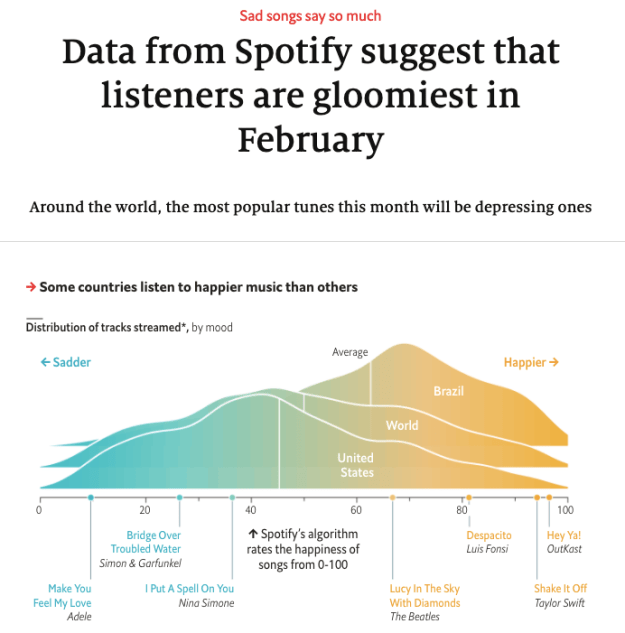
As histórias de classificação mostram quem ou o que se sai pior ou melhor em um conjunto de dados, ou onde uma entidade específica de interesse (a polícia local, escolas ou um setor econômico) se compara a outras.
As histórias típicas nesta categoria podem incluir “O bairro X é uma das piores áreas para o crime” ou “Escola Y está entre os melhores desempenhos do país”.
Você pode se concentrar nos lugares “mais atingidos”, como em “Área em Birmingham está entre as 10 do Reino Unido mais afetadas pelos avanços do Crédito Universal“, ou pode observar como seu setor se compara a outros, como em “Construção é a terceira indústria mais perigosa do Reino Unido”.
Mas as histórias de classificação também podem ser sobre os melhores ou piores momentos, lugares ou categorias que um conjunto de dados “revela”.
O artigo do The Economist, por exemplo, fala sobre o mês no qual as pessoas mais escutam canções tristes. Uma história do Birmingham Live, por outro lado, mostra os crimes mais comuns em Sandwell – e onde você provavelmente será uma vítima.
Ângulo 4: Variação – “loterias de códigos postais”, mapas e distribuições
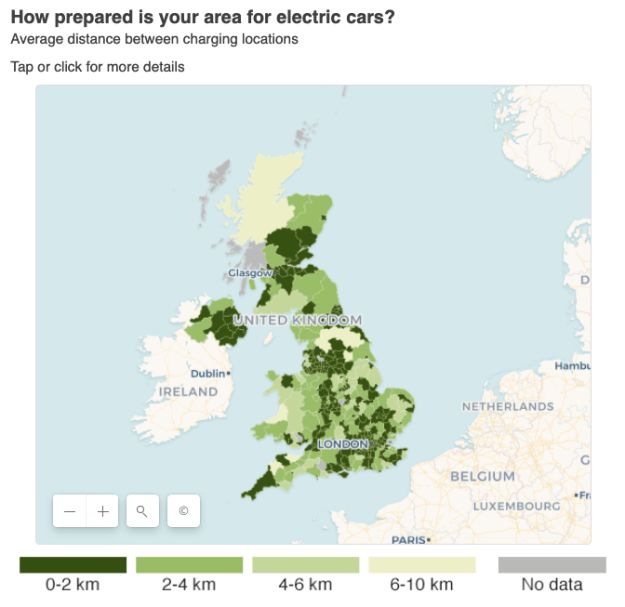
As histórias de variação funcionam melhor quando esperamos tratamento igualitário em alguma situação.
O exemplo clássico usa um mapa coroplético ou mapa de calor para mostrar como algumas partes de um país têm menos acesso a algo, ou mais demanda por algo, do que outras partes.
A frase “loteria postal”, por exemplo, reflete a sensação de que o acesso de uma pessoa a algo que deveria ser igualmente distribuído é, na verdade, um jogo de azar.
A história contada pelo núcleo de jornalismo de dados da BBC “FIV: casais do NHS ‘enfrentam racionamento social’“, por exemplo, mapeia como moradores de diferentes regiões da Inglaterra têm mais ou menos acesso a tratamento de fertilidade.
Uma história de variação pode revelar que a injustiça existe – ou, se as pessoas estão cientes disso, precisamente como e onde ela ocorre (especialmente em sua área).
Histórias de investigações algorítmicas (algorithmic accountability) como a Machine Bias, da ProPublica, muitas vezes são sobre variação e injustiça reveladas quando um algoritmo não é aplicado: podem ser pessoas sendo sentenciadas de forma diferente ou recebendo cotações de seguro diferentes, apesar de nenhuma diferença significativa entre elas.
Uma história de variação pode igualmente ser usada para destacar áreas de demanda mal servida ou falta de oferta: uma matéria que fiz com o Núcleo de Dados Compartilhados da BBC sobre pontos de recarga de carros elétricos envolvia identificar quanta infraestrutura existia no país e onde. A imagem que os dados trouxeram forneceu uma base para estudos de caso e reações.
Ângulo 5. ‘Explorar’: ferramentas, interatividade – e arte

Ângulos exploratórios são, em grande parte, nativos da web. O seu argumento de venda é frequentemente caracterizado por um “apelo à ação”, como “explore”, “jogue” ou “faça o teste”. Mas também pode destacar a conclusão da análise, como “cada X que já aconteceu”, ou simplesmente responder a perguntas como “Quem / como / onde”.
Os leitores são frequentemente convidados a explorar os dados em uma história explicativa para gerar uma versão pessoal dela, a partir de questionários como os da BBC “7 bilhões de pessoas e você: Qual é o seu número”’, do New York Times “Faça o Quiz: Você Conseguiria Se Virar Como Um Americano Pobre ?”, ou com mapas interativos, como o LA Times: “Cada foto que Kobe Bryant já fez. Todos os 30.699 cliques”’.
Essa categoria também inclui simuladores, como o do Washington Post em “Por que surtos como o coronavírus se espalham exponencialmente e como ‘nivelar a curva’”, e o de Matt Korostoff em “Riqueza demonstrada em escala”, além de jogos, calculadoras e chatbots, entre outros formatos.
Mas histórias exploratórias não precisam ser interativas: “Quem está morrendo de coronavírus e em qual unidade do NHS?”?”, do The Guardian, é uma história exploratória ao oferecer amplas percepções e um mapa estático, mas não oferece nenhum controle particular ao leitor, assim como as excelentes visualizações montadas pela Bloomberg em How Americans Die. Apesar de permitirem alguma interação com os gráficos, é fortemente orientada pelo autor.
As histórias exploratórias também podem ser bastante peculiares e aparecem até mesmo em forma de arte. “Sweet Love: canções populares de casamento reimaginadas como cupcakes”, por exemplo, é simplesmente uma exploração do que acontece quando as listas de reprodução são tratadas como dados e esses dados são visualizados de uma maneira particular.
Ângulo 6. Correlação: quando as coisas estão conectadas – ou não

Jornalistas muitas vezes procuram estabelecer relações olhando para os dados, mas isso pode ser problemático: correlação, é claro, não é igual a causalidade. Mesmo que duas coisas possam estar subindo ou descendo ao mesmo tempo, não significa que os dois estão relacionados, como o The Guardian explora em “O aumento do crime violento é devido a cortes no policiamento de bairro?”.
Por essa razão, talvez você veja com a mesma frequência uma história desmascarando uma relação entre dois pontos de dados, e uma tentando tentando estabelecer que X está causando Y.
O FactCheck do Channel 4 News, por exemplo, analisou os dados para responder a pergunta “Os migrantes estão causando a crise A&E?”, mas não encontrou relação entre o tamanho da população não-britânica em uma área específica e o desempenho do departamento de Acidentes e Emergências (A&E) dos hospitais locais.
A complexidade que envolve essas análises faz com que qualquer história com o ângulo de relacionamento provavelmente seja bastante explanatória – ou pelo menos precisa ser explanatória para comunicar essas ressalvas.
O “The Economist”, em “’Como uma obsessão com a casa própria pode arruinar a economia”, passou mais de 12 minutos explorando a relação entre essas duas variáveis, em vez de apresentar a história como uma simples afirmação de que a casa própria está arruinando a economia.
As histórias de relacionamento não precisam ser sobre correlação: uma networking analysis pode ser outra maneira de contar histórias baseadas em relações estabelecidas de fato, como doações, cargos de diretoria, conexões familiares, seguidores de mídia social ou outras interações.
O projeto “Investigando a porta giratória do Google”, por exemplo, usa dados para expor o número de pessoas que se deslocam entre o gigante da tecnologia e órgãos do governo, enquanto “No mundo da arte de Seattle, mulheres dirigem o show”, do The Seattle Times, usa uma visualização de diagrama de rede para contar a história das conexões dentro da cena artística local (construída pedindo às mulheres “na comunidade artística da área de Seattle para nomear mentores, colaboradores e colegas que influenciaram suas carreiras”).
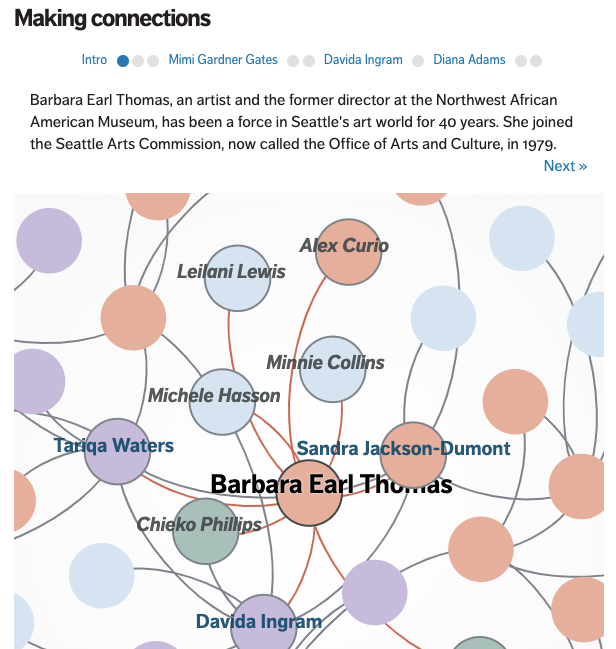
Mas até mesmo a networking analysis pode sofrer com a falta de concretude: uma conexão entre duas pessoas ou um movimento entre organizações é raramente uma prova isolada de corrupção ou a causa de decisões suspeitas.
Por esse motivo, a networking analysis também é frequentemente apresentada como uma história exploratória (“Doações políticas australianas 2016-17: quem deu o que a quais partidos”), como parte de um recurso explicativo (“Império corporativo do Radiohead: dentro dos dólares e centavos da banda”), ou o processo é usado para identificar um único ponto de dados com base em seus relacionamentos, que então informam relatórios adicionais (“Top Tory tem vínculo familiar com um banqueiro offshore que deu £ 800.000 à parte”).
Muitas das histórias que saíram dos Panama Papers, por exemplo, enquadram-se nesta última categoria. The Power Players, do ICIJ, é um ângulo exploratório das várias histórias que os documentos ajudaram a revelar.
A história China conectada, da Reuters, é um dos melhores exemplos de como navegar pelos desafios da narrativa baseada em rede, guiando você cuidadosamente pelas estruturas de poder mapeados e permitindo que você explore-as ao longo do caminho.
Ângulo 7: Problemas e soluções: histórias sobre ‘dados ruins, ‘não há dados’ e ‘obtenha os dados’

A última categoria pode soar um pouco “meta”, pois são as histórias sobre os dados em si: a falta de dados, os problemas com eles, ou simplesmente sua disponibilidade – mas isso não significa que não possa ser uma boa história.
Histórias de “dados ruins” podem ser incrivelmente importantes: o poder é exercido, o dinheiro é gasto e as vidas são afetadas com base em dados. Portanto, se houver falhas nos dados, o exercício do poder provavelmente também será falho.
Histórias de investigações algorítmicas também podem, por exemplo, revelar os dados falhos que sustentam esses algoritmos, como em “Risco Aumentado”, do Der Spiegel.
De modo geral, dados costumam ser a base de alegações políticas de sucesso ou acusações de fracasso. Se uma força policial está subnotificando o crime, um país atingido por um furacão está relatando mortes incorretamente, ou os testes de COVID-19 estão sendo reportados de maneira errada, há o risco de quem está no poder fazer afirmações falsas.
Ideias de histórias de dados ruins podem vir dessas alegações, ou de alguém que passou pelo sistema e encontrou lacunas, ou simplesmente após você mesmo examinar os dados existentes em busca de características problemáticas: a história do The Guardian sobre “dados de moradores de rua não são adequados para o propósito”, e este artigo da BBC sobre preocupações com dados de remuneração por gênero vieram de jornalistas que perceberam falhas nas bases de dados.
Essas falhas também podem levar a histórias de acompanhamento em que melhores dados são buscados por meio de fontes alternativas, como nesta história sobre números de sem-teto, do meu colega da BBC Dan Wainwright.
Um ângulo para uma história sobre dados é a história de quando não há dados disponíveis: muitas vezes, a falta de dados sobre um assunto representa uma falta de interesse político naquele tema, ou vontade de abordá-lo.
Esses casos geralmente relatam preocupações sobre transparência ou falta de informações.
A investigação do BMJ “As escolas médicas estão fechando os olhos para o racismo?”, por exemplo, começa com o trecho: “As escolas de medicina no Reino Unido estão mal preparadas para lidar com o racismo e o assédio racial experimentado por estudantes de minorias étnicas”, enquanto uma investigação do BIJ sobre as emissões agrícolas ressalta que “o governo monitora apenas as emissões de amônia das maiores granjas de aves ou fazendas de suínos, não contabilizando, principalmente, os maiores poluidores – fazendas leiteiras e de carne bovina.
A matéria da VICE baseada em Lei de Acesso à Informação “7 Universidades dizem ter ‘zero’ relatórios sobre violência sexual” traz a fala de um especialista:
“O fato de algumas universidades não terem recebido relatórios não significa que não há assédio sexual naquelas universidades”, disse Jess Asato, líder de políticas na Safelives, uma organização britânica dedicada à violência doméstica. “Isso significa que eles não conseguiram lidar com isso como uma questão que exige uma mudança cultural organizacional completa”.
Mulheres Invisíveis, de Caroline Criado Perez, é um exemplo de livro inteiro dedicado a uma “lacuna de dados” – leitura imprescindível para qualquer jornalista de dados não só como exemplo das histórias que podem ser contadas, mas também porque destaca uma série de problemas a serem considerados com dados e os quais você pode ter que lidar durante suas investigações.
Se os dados hoje ausentes chegaram a ser publicados em algum momento no passado, a história pode se concentrar na decisão de parar de publicá-los. Em “Médicos legistas da Flórida estavam divulgando dados de morte por coronavírus . O estado os fez parar”, do The Tampa Bay Times, é um exemplo, e ocasionalmente pode servir de base para um editorial, como este do The Chicago Reporter sobre a retirada do ar da API da polícia.
Ocasionalmente, a falta de dados pode obrigar um veículo de imprensa, jornalista ou ativista a compilar seus próprios dados – ponto em que você tem uma história sobre como “obter os dados”.

Talvez os exemplos mais famosos desse tipo de história sejam The Counted, do The Guardian, e Força Fatal, do Washington Post, que giram em torno de pessoas mortas por policiais. E eu escrevi anteriormente sobre exemplos semelhantes em Dar voz aos (literalmente) sem voz: jornalismo de dados e os mortos.
Outros exemplos se concentram nos ativistas que tentam resolver o problema, no que pode se tornar uma história de interesse parcialmente humano: “Ninguém rastreia com precisão os trabalhadores de saúde vítimas da COVID-19. Então, ela fica acordada à noite catalogando os mortos”,’da ProPublica, e esta história sobre programadores brasileiros construindo contagens alternativas de Covid-19 são dois casos recentes.
No entanto, as histórias de “obter os dados” não precisam ser tão ambiciosas ou pessoais. No início da última década, muitos posts do Guardian Datablog compartilhavam bases de dados que equipes encontravam, limpavam e organizavam.

Muitos posts do blog Guardian Datablog convidam o leitor a ‘acessar os dados’
É claro que a novidade de meramente disponibilizar dados desapareceu na última década, e alguns jornalistas apenas colocam seus dados no GitHub em vez de escrever um artigo sobre isso.
Mas, se você obteve alguns dados interessantes que não estão disponíveis em outro lugar, por exemplo, através da combinação de vários conjuntos de dados, usando Lei de Acesso à Informação ou raspagem, então há muito valor em compartilhar isso com o seu público como um ato de construção de relacionamento e – no melhor dos casos – construção da comunidade.
O ponto a ser lembrado aqui é que, se você quiser construir uma comunidade, os dados por si só não farão o trabalho para você: envolver colaboradores em potencial (por exemplo, através da organização de hackdays) pode tornar mais provável que eles construam em cima de seu valioso trabalho de dados.
Mais um ângulo: encontrar histórias através dos dados, e não nos dados
Após ter mapeado esses sete ângulos prováveis em histórias baseadas em dados, vale enfatizar que há outro tipo de história que nenhuma delas pode cobrir: as histórias em que os dados são o meio pelo qual uma entrevista, evento, documento ou relacionamento é descoberto ou destacado, permitindo ao jornalista encontrar a história por trás disso.
Você pode chamar isso de “ponto de dados único” ou uma história de “’agulha no palheiro”.
Em uma postagem anterior no blog, explorei algumas dessas técnicas, desde entrevistar indivíduos conectados a um único ponto de dados (por exemplo, alguém que dirige uma igreja em uma cidade menos religiosa do Reino Unido) até buscar atualizações de uma organização responsável por lidar com os números que você está analisando.
Muitas histórias investigativas, por exemplo, usam técnicas de jornalismo de dados para ajudar a direcionar suas entrevistas e solicitações de Lei de Acesso à Informação, ou escolher quais locais visitar, à medida que constroem uma imagem maior de um problema sistêmico.
Portanto, embora esses sete ângulos sejam úteis para gerar ideias e fazer um brainstorming editorial para um conjunto de dados, eles não devem ser o limite de suas opções: qualquer história pode se beneficiar das técnicas de jornalismo de dados.

Thaanks for writing