I’ve been focusing so much on blogging the bells and whistles stuff that Google Refine does that I’ve never actually written about its most simple function: cleaning data. So, here’s what it does and how to do it:
- Download and install Google Refine if you haven’t already done so. It’s free.
- Run it – it uses your default browser.
- In the ‘Create a new project’ window click on ‘Choose file‘ and find a spreadsheet you’re working with. If you need a sample dataset with typical ‘dirty data’ problems I’ve created one you can download here.
- Give it a project name and click ‘Create project‘. The spreadsheet should now open in Google Refine in the browser.
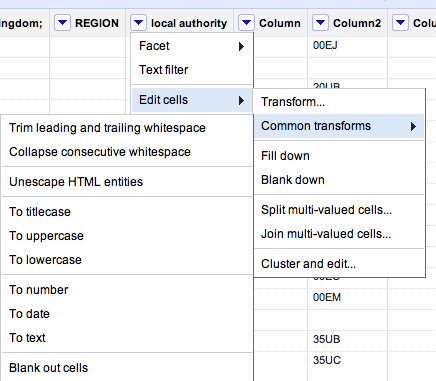
- At the top of each column you’ll see a downward-pointing triangle/arrow. Click on this and a drop-down menu opens with options including Facet; Text filter; Edit cells; and so on.
- Click on Edit cells and a further menu appears.
- The second option on this menu is Common transforms. Click on this and a final menu appears (see image below).
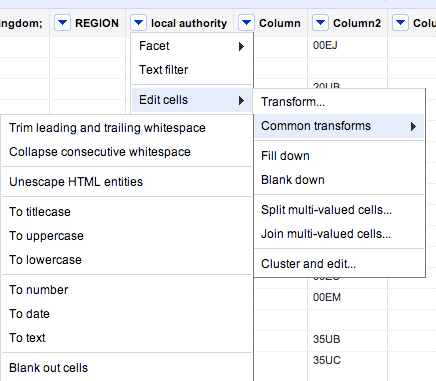
You’ll see there are a range of useful functions here to clean up your data and make sure it is consistent. Here’s why:
Trim leading and trailing whitespace
Sometimes in the process of entering data, people put a space before or after a name. You won’t be able to see it, but when it comes to counting how many times something is mentioned, or combining two sets of data, you will hit problems, because as far as a computer or spreadsheet is concerned, ” Jones” is different to “Jones”.
Clicking this option will remove those white spaces.
Collapse consecutive whitespace
Likewise, sometimes a double space will be used instead of a single space – accidentally or through habit, leading to more inconsistent data. This command solves that problem.
Unescape HTML entities
At some point in the process of being collected or published, HTML may be added to data. Typically this represents punctuation of some sort. “"” for example, is the HTML code for quotation marks. (List of this and others here).
This command will convert that cumbersome code into the characters they actually represent.
To titlecase/To uppercase/To lowercase
Another common problem with data is inconsistent formatting – occasionally someone will LEAVE THE CAPS LOCK ON or forget to capitalise a name.
This converts all cells in that column to be consistently formatted, one way or another.
To number/To date/To text
Like the almost-invisible spaces in data entry, sometimes a piece of data can look to you like a number, but actually be formatted as text. And like the invisible spaces, this becomes problematic when you are trying to combine, match up, or make calculations on different datasets.
This command solves that by ensuring that all entries in a particular column are formatted the same way.
Now, I’ve not used that command much and would be a bit careful – especially with dates, where UK and US formatting is different, for example. If you’ve had experiences or tips on those lines let me know.
Other transforms
In addition to the commands listed above under ‘common transforms’ there are others on the ‘Edit cells’ menu that are also useful for cleaning data:
Split / Join multi-valued cells…
These are useful for getting names and addresses into a format consistent with other data – for example if you want to split an address into street name, city, postcode; or join a surname and forename into a full name.
Cluster and edit…
A particularly powerful cleaning function in Google Refine, this looks at your column data and suggests ‘clusters’ where entries are similar. You can then ask it to change those similar entries so that they have the same value.
There is more than one algorithm (shown in 2 drop-down menus: Method and Keying function) used to cluster – try each one in turn, as some pick up clusters that others miss.
If you have any other tips on cleaning data with Google Refine, please add them.